Write once, run anywhere - 한 번 쓰면, 어디서든 실행된다.
Java를 대표하는 이 문구는 1990년대 중반부터 지금까지 유효하다. 백엔드 개발자라면 한 번쯤은 접하게 되는 Java와 Spring – 이 글에서는 Java가 왜 멀티스레드 언어인지, Spring Boot가 어떻게 이를 활용하여 대규모 트래픽을 처리하는지, 그리고 Node.js와 어떤 구조적 차이가 있는지를 정리한다.
1. Java의 역사와 철학
탄생 배경
Java의 역사는 1990년대 초반으로 거슬러 올라간다. 원래 오크(Oak)라는 이름으로 선 마이크로시스템즈(Sun Microsystems)의 프로젝트에서 탄생했다. 이 프로젝트의 원래 목표는 소비자 가전제품을 위한 언어 개발이었지만, 오크는 특정 플랫폼에 국한되지 않는 범용적인 프로그래밍 언어로 발전하게 됐다.
창시자인 제임스 고슬링(James Gosling)이 자바 커피 애호가였기에 자바 커피의 원산지인 자바(Java) 섬에서 이름을 따왔다. 1995년에 정식 발표된 이후, Java는 폭발적인 인기를 끌게 되었다.
JVM과 바이트코드
Java를 다른 컴파일 언어와 구분 짓는 가장 큰 특징은 컴파일된 코드가 크로스 플랫폼이라는 것이다. Java 컴파일러는 .java 파일을 바이트코드(bytecode)라는 특수한 바이너리 형태로 변환하고, 이 바이트코드를 실행하기 위해 JVM(Java Virtual Machine)이 필요하다. JVM은 자바 바이트코드를 어느 플랫폼에서나 동일한 형태로 실행시킨다.
C 언어와 비교하면 그 차이가 분명해진다.
- C 언어: 소스 코드를 컴파일하면 CPU가 직접 실행할 수 있는 실행 파일이 생성된다. 하지만 이 실행 파일은 OS와 CPU 아키텍처에 종속된다. Windows에서는
a.exe, macOS에서는a.out이 나오는 식이다. - Java: 소스 코드를 JVM이 이해할 수 있는 수준(바이트코드)까지만 컴파일한다. 나머지는 JVM이 인터프리팅하여 애플리케이션을 실행한다.
이러한 구조 때문에 Java는 컴파일러와 인터프리터의 속성을 모두 가진 하이브리드 언어로 분류된다. 1990년대 중반에 크로스 플랫폼을 실현했다는 것은 당시로서는 혁신적인 아이디어였다.
“인터프리터 방식이면 느리지 않나?“라는 의문이 들 수 있다. 초기 JVM은 실제로 느렸지만, 현대 JVM에는 JIT 컴파일러(Just-In-Time Compiler)가 탑재되어 있다. JIT 컴파일러는 바이트코드를 실행하면서 자주 호출되는 핫 코드(hot code) 경로를 감지하고, 이를 해당 플랫폼의 네이티브 코드로 변환하여 캐싱한다. 이후 동일 코드가 호출되면 인터프리팅 없이 네이티브 코드가 직접 실행된다.
덕분에 Java는 런타임에 점점 빨라지는 워밍업(warm-up) 특성을 갖게 되었고, 충분히 워밍업된 Java 애플리케이션은 C/C++에 준하는 실행 성능을 보여줄 수 있다.
Java의 현재 위상
30년이 지난 지금도 Java는 건재하다. JetBrains의 2024년 개발자 생태계 조사에 따르면 Java는 여전히 가장 많이 사용되는 프로그래밍 언어 중 하나이며, 특히 엔터프라이즈 백엔드 영역에서는 압도적인 점유율을 유지하고 있다.
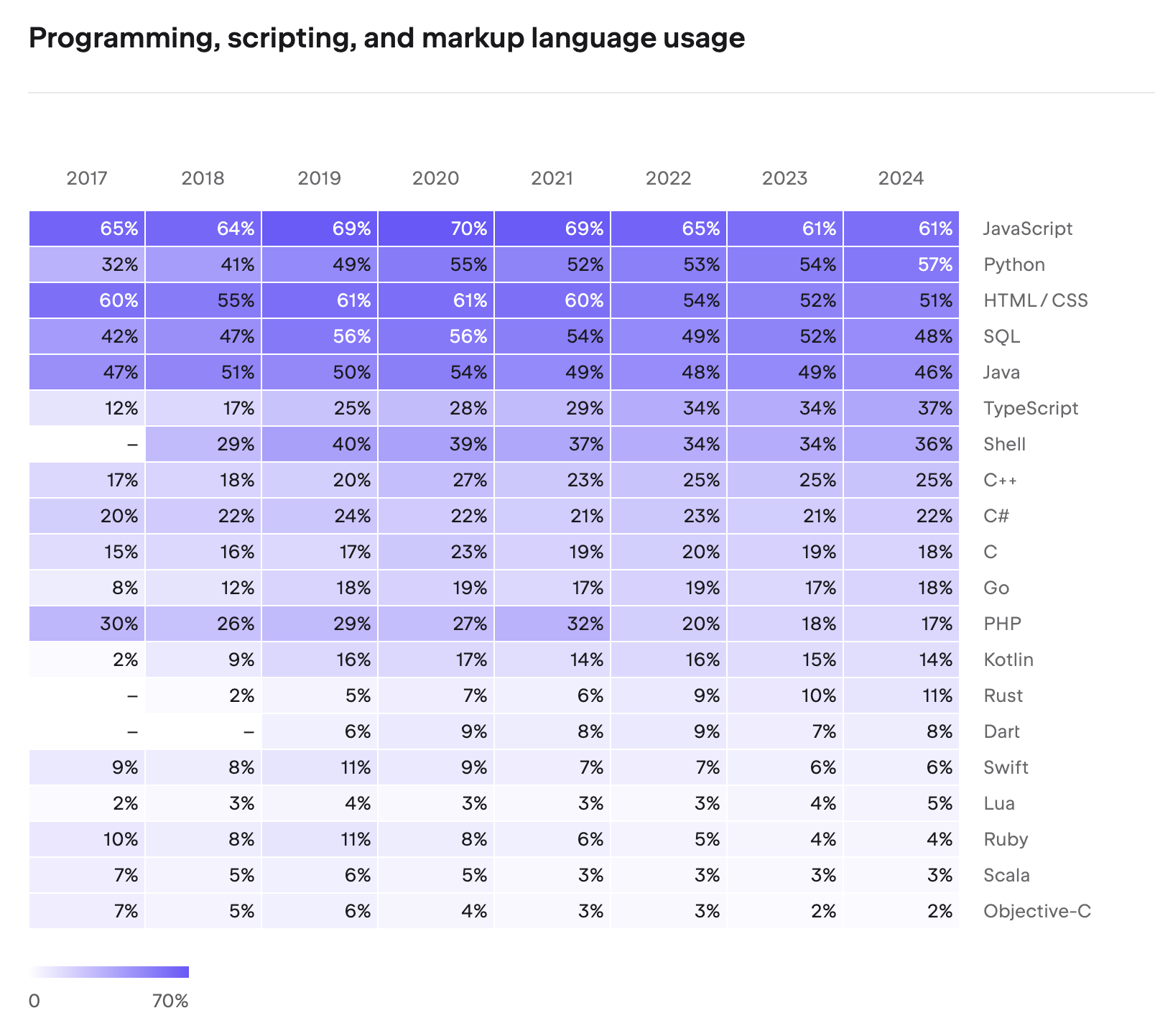
금융, 통신, 공공 등 미션 크리티컬한 시스템에서 Java가 선택되는 이유는 안정성, 성숙한 생태계, 그리고 하위 호환성에 대한 신뢰 때문이다. Java 8에서 작성된 코드가 Java 21에서도 문제없이 동작한다는 것은 다른 언어에서는 쉽게 찾아보기 어려운 강점이다.
Java의 다섯 가지 철학
1991년에 발표된 Java의 다섯 가지 핵심 철학은 다음과 같다.
- 객체 지향 방법론을 사용해야 한다.
- 같은 프로그램(바이트코드)이 여러 운영 체제에서 실행될 수 있어야 한다.
- 컴퓨터 네트워크 접근 기능이 기본으로 탑재되어 있어야 한다.
- 원격 코드를 안전하게 실행할 수 있어야 한다.
- 다른 객체 지향 언어들의 좋은 부분만 가져와 사용하기 편해야 한다.
C++가 1983년에 발표되면서 객체 지향 개념이 확산되기 시작했고, 1990년대에 접어들면서 소프트웨어 공학의 핵심 패러다임으로 자리 잡았다. 객체지향의 재사용성, 확장성, 유지보수 용이성을 품은 Java의 등장은 큰 여파를 몰고 올 수밖에 없었다.
이 다섯 가지 철학은 이후 Java 생태계가 발전하는 방향을 결정짓는 나침반이 되었다. 크로스 플랫폼(2번)은 JVM이, 네트워크 기능(3번)과 원격 코드 실행(4번)은 이후 등장하는 Servlet과 EJB가, 그리고 객체 지향(1번)과 편의성(5번)은 Spring 프레임워크가 각각 계승하게 된다.
JDK와 Java 에디션
Java 프로그램을 개발하려면 JDK(Java Development Kit)가 필요하다. JDK는 Java 컴파일러(javac), JVM, 표준 라이브러리, 디버거 등 개발에 필요한 도구를 모두 포함하는 개발 키트다. 반면 Java 프로그램을 실행만 하려면 JRE(Java Runtime Environment)만 있으면 된다. JRE는 JVM과 표준 라이브러리만 포함하며, JDK의 부분 집합이다. Java 11부터는 JRE가 별도로 배포되지 않고 JDK에 통합되었다.
Java의 인기와 함께 용도에 따른 다양한 에디션이 등장했다.
- Java SE(Standard Edition): JVM, 핵심 API, 표준 라이브러리를 포함하는 기본 에디션이다. 우리가 “JDK를 설치한다"고 할 때 설치하는 것이 바로 Java SE의 구현체다.
- Java EE(Enterprise Edition): Java SE 위에 서버 개발에 필요한 기술 스펙을 추가한 에디션이다. Servlet, JSP, EJB 등 엔터프라이즈 환경에서 필요한 API들이 포함된다.
- Java ME(Micro Edition): 임베디드 기기, 모바일 기기 등 리소스가 제한된 환경에 특화된 에디션이다.
Servlet과 웹 개발의 혁신
Java의 다섯 가지 철학 중 3번(네트워크 접근 기능)과 4번(원격 코드 실행)을 웹 개발 영역에서 실현한 것이 바로 Servlet이다. Servlet은 Java EE에 포함된 서버 사이드 컴포넌트로, HTTP 요청을 받아 처리하고 응답을 반환하는 인터페이스다. Servlet이 등장하기 전에는 웹 서버에서 동적 콘텐츠를 생성하려면 CGI(Common Gateway Interface)를 사용해야 했는데, CGI는 요청마다 새로운 프로세스를 생성하는 비효율적인 구조였다. Servlet은 이를 스레드 기반으로 전환하여 성능과 생산성을 모두 높였다.
@WebServlet(name = "helloServlet", urlPatterns = "/hello")
public class HelloServlet extends HttpServlet {
@Override
protected void service(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String username = request.getParameter("username");
response.setContentType("text/plain");
response.setCharacterEncoding("utf-8");
response.getWriter().write("hello " + username);
}
}
Java EE에서 Jakarta EE, 그리고 Spring으로
Servlet과 EJB를 중심으로 Java EE는 엔터프라이즈 개발의 표준이 되었다. 하지만 EJB는 철학은 좋았으나 현실은 달랐다. 수십 줄의 XML 설정, 복잡한 인터페이스 구현, 무거운 애플리케이션 서버 의존성 등 “간단한 비즈니스 로직 하나를 구현하는 데 왜 이렇게 많은 코드가 필요한가?“라는 불만이 커졌다.
2000년대 초반, 이 복잡함에 불만을 품은 로드 존슨(Rod Johnson)이 Expert One-on-One J2EE Design and Development 라는 책을 출판했다. 이 책에서 제시한 경량 컨테이너 아이디어가 하이버네이트(Hibernate)와 결합되어 2003년에 Spring Framework가 탄생했다. “EJB의 겨울 뒤에 봄이 온다"는 의미로 Spring이라는 이름이 붙었다.
Spring은 Java의 다섯 가지 철학을 계승하면서도 개발자 편의성을 극대화했다. 의존성 주입(DI)과 관점 지향 프로그래밍(AOP)을 통해 객체 지향의 장점을 살리면서도 보일러플레이트 코드를 대폭 줄였다. 또한 Servlet을 내부적으로 활용하되, 개발자가 Servlet API를 직접 다룰 필요 없이 @Controller와 @RequestMapping 같은 어노테이션으로 웹 개발을 할 수 있게 추상화했다.
한편, 선 마이크로시스템즈가 2010년 오라클에 인수된 후 Java EE의 발전 방향에 대한 커뮤니티의 우려가 커졌다. 결국 오라클은 2017년 Java EE를 Eclipse Foundation에 이전하기로 결정했고, 상표권 문제로 Jakarta EE라는 이름으로 변경되었다. 이를 통해 커뮤니티 주도의 오픈소스 개발이 본격화되었다.
2. Spring의 멀티스레딩 아키텍처
프로세스와 스레드 기초
Spring의 멀티스레딩을 이해하려면 먼저 프로세스와 스레드의 개념을 짚어야 한다.
프로그램은 디스크에 저장된 데이터이고, 이를 실행시키면 메모리에 적재되어 프로세스가 된다. CPU는 메모리에 있는 다양한 프로세스들을 빠르게 전환하며 실행해서, 여러 프로세스가 동시에 돌아가는 것처럼 보이게 한다.

프로세스는 code, data, heap, stack 네 가지 영역으로 구성된다.

각 영역의 역할은 다음과 같다.
- Code: 컴파일된 프로그램의 명령어(기계어 코드)가 저장되는 영역이다. 읽기 전용이며, 프로세스가 실행하는 모든 함수와 로직이 여기에 위치한다.
- Data: 전역 변수와
static변수가 저장되는 영역이다. 프로그램 시작 시 할당되어 종료 시까지 유지된다. - Heap:
new키워드 등으로 동적 할당되는 메모리 영역이다. 개발자가 런타임에 필요한 만큼 메모리를 요청하고, 사용이 끝나면 해제한다. Java에서는 GC(Garbage Collector)가 이 해제를 자동으로 처리한다. - Stack: 함수 호출 시 생성되는 지역 변수, 매개변수, 복귀 주소 등이 저장되는 영역이다. 함수가 호출될 때마다 스택 프레임이 쌓이고, 함수가 반환되면 해당 프레임이 제거된다.
다이어그램에서 메모리 주소가 위쪽이 0xFFFFFFFF(높은 주소), 아래쪽이 0x00000000(낮은 주소)으로 표기된 것을 볼 수 있다. 이것은 OS가 프로세스에게 부여하는 가상 메모리 주소 공간을 나타낸다. 32비트 시스템 기준으로 각 프로세스는 0부터 약 4GB(0xFFFFFFFF)까지의 주소 공간을 갖는다.
여기서 핵심적인 설계가 Heap과 Stack의 성장 방향이다. Heap은 낮은 주소에서 높은 주소 방향(↓)으로, Stack은 높은 주소에서 낮은 주소 방향(↑)으로 자란다. 두 영역이 서로 반대 방향으로 확장되기 때문에, 그 사이의 빈 공간(free space)을 최대한 효율적으로 활용할 수 있다. 만약 두 영역이 같은 방향으로 자란다면 한쪽이 넘칠 때 다른 쪽의 여유 공간을 활용할 수 없을 것이다. 이 설계 덕분에 Heap과 Stack은 서로의 여유 공간을 공유하며 유연하게 메모리를 사용할 수 있다.
싱글스레드 vs 멀티스레드
하나의 stack을 가진 프로세스를 싱글스레드(single thread)라고 한다. 스레드(thread)란 프로세스 안의 더 작은 실행 단위를 말한다.
멀티스레드(multi thread)는 하나의 프로세스 안에서 여러 stack을 두어 다양한 작업을 동시에 처리하는 것처럼 보이게 한다. 핵심은 code, data, heap 영역을 스레드들이 공유한다는 점이다. 이 덕분에 싱글스레드 프로세스를 여러 개 띄우는 것보다 오버헤드가 적다.

하지만 멀티스레드에는 치명적인 제약이 있다. 여러 스레드가 공유 데이터에 동시에 접근하여 값을 변경하려 하면 동시성 문제(Concurrency Problem)가 발생한다. 간단한 예시를 보자.
public class Counter {
private int count = 0;
public void increment() {
count++; // read → modify → write: 이 세 단계가 원자적이지 않다
}
public int getCount() {
return count;
}
}
두 스레드가 동시에 increment()를 호출하면, 둘 다 같은 값을 읽고 1을 더해 저장하여 결과적으로 1만 증가하는 경쟁 조건(Race Condition)이 발생할 수 있다. synchronized 키워드로 이를 방지할 수 있다.
public class Counter {
private int count = 0;
public synchronized void increment() {
count++; // 한 번에 하나의 스레드만 실행 가능
}
public synchronized int getCount() {
return count;
}
}
이를 방지하기 위해 synchronized 외에도 스핀락(Spinlock), 세마포어(Semaphore), java.util.concurrent 패키지의 AtomicInteger 등 다양한 동기화 메커니즘이 제공된다.
Spring에서의 함정: Spring의 기본 빈 스코프는 싱글톤(Singleton)이다. 즉, 모든 요청 스레드가 같은 빈 인스턴스를 공유한다. 따라서 빈에 상태(인스턴스 변수)를 두면 위와 동일한 동시성 문제가 발생한다. Spring 빈은 항상 무상태(stateless)로 설계해야 한다.
// BAD - 싱글톤 빈에 상태를 저장하면 스레드 간 데이터가 꼬인다
@Service
public class OrderService {
private int todayOrderCount = 0; // 모든 스레드가 공유!
public void placeOrder() {
todayOrderCount++; // Race Condition 발생
}
}
// GOOD - 상태는 DB나 외부 저장소에 위임
@Service
public class OrderService {
private final OrderRepository orderRepository;
public void placeOrder(Order order) {
orderRepository.save(order); // DB의 트랜잭션이 동시성을 관리
}
}
Java의 멀티스레드 구현
Java는 언어 레벨에서 두 가지 방식으로 멀티스레드를 지원한다.
Thread 클래스 상속 방식:
public class MyThread extends Thread {
public void run() {
System.out.println("Thread 실행!");
}
}
new MyThread().start();
Runnable 인터페이스 구현 방식:
public class MyRunnable implements Runnable {
public void run() {
System.out.println("Runnable 실행!");
}
}
new Thread(new MyRunnable()).start();
직접 멀티스레드를 구현할 때는 Lock과 synchronized 키워드를 통해 동기화를 직접 관리해야 한다. 하지만 Spring Boot에서는 스레드풀(Thread Pool) 개념을 통해 이를 훨씬 편리하게 다룰 수 있다.
Tomcat의 스레드풀
스레드풀(Thread Pool)은 멀티스레딩을 효율적으로 관리하기 위해 스레드를 미리 생성해 둔 풀이다. 새 작업이 요청되면 풀에 있는 유휴 스레드가 작업을 수행하고, 작업이 끝나면 스레드는 다시 풀에 반환된다. 이를 통해 스레드 생성/소멸의 오버헤드를 줄이고 응답 시간을 단축할 수 있다.
Spring Boot에서 스레드풀 관리는 정확히 말하면 Spring Boot 자체가 아니라, 내장된 Tomcat(서블릿 컨테이너)이 담당한다.

위 다이어그램에서 핵심 역할을 하는 것이 DispatcherServlet이다. Spring MVC의 프론트 컨트롤러(Front Controller) 패턴을 구현한 것으로, 모든 HTTP 요청을 단일 진입점에서 받아 적절한 Controller로 라우팅한다. 개발자가 URL마다 서블릿을 매핑할 필요 없이, @RequestMapping 어노테이션만으로 요청 처리를 정의할 수 있는 이유가 바로 DispatcherServlet 덕분이다.

Tomcat은 HTTP 요청을 처리하는 서블릿 컨테이너다. 복잡한 HTTP Request 구조를 개발자 대신 파싱해준다.
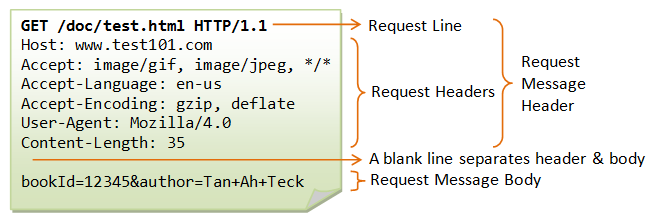
초기 Tomcat(3.2 이전)에서는 요청마다 스레드를 새로 생성하고 작업 후 소멸시켰다. 동시다발적 요청에 대해 매번 스레드를 만드는 것은 큰 부하를 유발했기 때문에, 스레드를 미리 생성하여 풀에 보관하는 방식으로 전환되었다.

HTTP Request가 들어오면 Queue에 Task가 전달되고, idle 상태의 스레드가 작업을 할당받는다. application.yaml에서 스레드풀을 설정할 수 있다.
server:
tomcat:
threads:
max: 200 # 생성할 수 있는 thread의 총 개수
min-spare: 10 # 항상 활성화되어 있는(idle) thread의 개수
accept-count: 100 # 작업 큐의 사이즈
기본적으로 최대 200개의 스레드를 생성할 수 있으며, 최소 10개의 유휴 스레드를 유지한다. 작업 큐에는 최대 100개의 대기 작업을 보관할 수 있다. 이 값들은 CPU 사용량과 요청 패턴에 따라 적절히 조정해야 한다.
HikariCP 커넥션풀
서블릿 컨테이너인 Tomcat이 요청 자체를 멀티스레드로 처리한다는 것을 알았다. 그렇다면 데이터베이스와의 연결은 어떻게 처리될까?
DB에 데이터를 읽고 쓸 때마다 커넥션을 새롭게 생성하는 것 자체가 큰 오버헤드를 갖고 있다. 이를 해결하기 위해 스레드풀과 동일한 발상으로 커넥션풀(Connection Pool)을 사용한다. 커넥션을 미리 만들어 두고 필요할 때 가져다 쓰는 것이다.
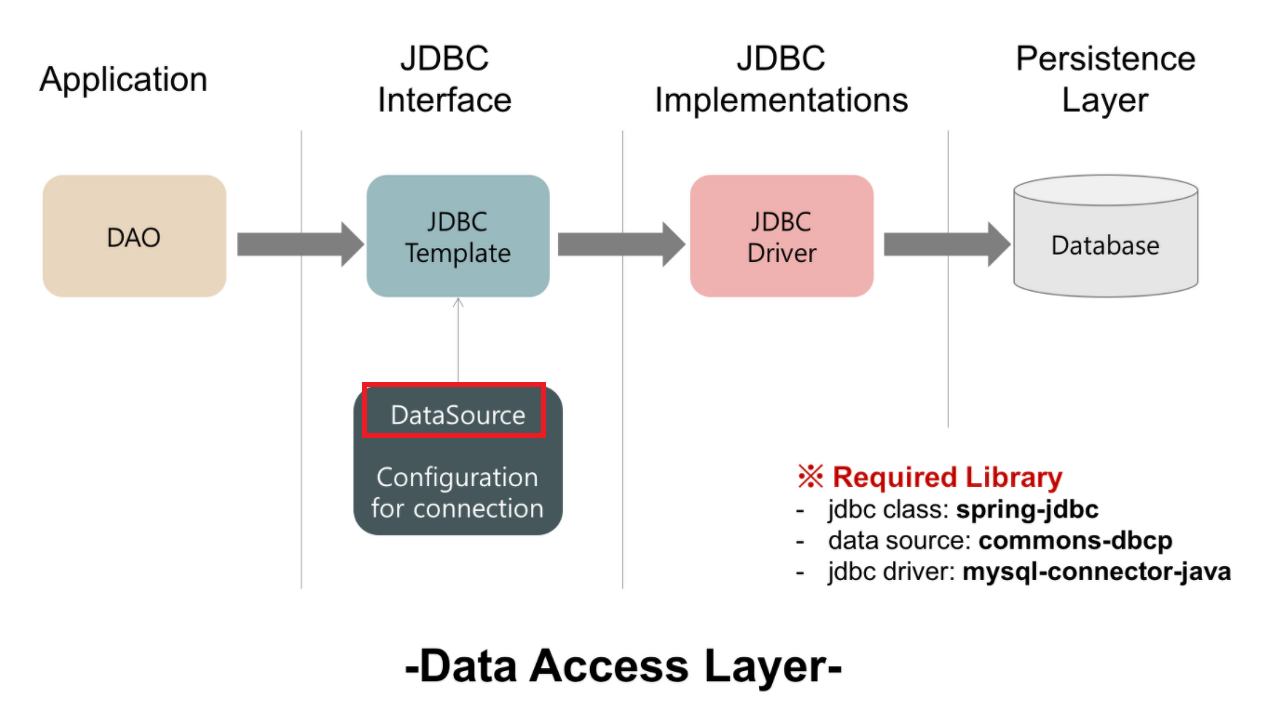
Spring 진영에서 데이터베이스 연결에 사용하는 표준 인터페이스가 JDBC(Java Database Connectivity)이다. Spring Boot 2.0부터는 HikariCP가 기본 커넥션풀로 채택되었다. application.yaml에서 다음과 같이 설정한다.
spring:
datasource:
url: jdbc:mysql://localhost:3306/mydb
username: myuser
password: mypassword
hikari:
maximum-pool-size: 10 # 최대 커넥션 수
connection-timeout: 5000 # 커넥션 획득 대기 시간(ms)
connection-init-sql: SELECT 1
validation-timeout: 2000 # 커넥션 유효성 검사 시간(ms)
minimum-idle: 10 # 최소 유휴 커넥션 수
idle-timeout: 600000 # 유휴 커넥션 유지 시간(ms)
max-lifetime: 1800000 # 커넥션 최대 수명(ms)
멀티스레드 환경에서 동시에 데이터를 쓸 때 발생하는 동시성 문제는 HikariCP와 데이터베이스의 트랜잭션 메커니즘이 처리해준다.
정리하면, Spring Boot가 멀티스레드 애플리케이션이라 불리는 이유는 다음과 같다.
- Tomcat 스레드풀: HTTP 요청을 멀티스레드로 처리
- HikariCP 커넥션풀: DB I/O를 멀티스레드로 처리
- JVM: Java의 Thread 클래스와 바이트코드 실행 자체를 멀티스레드로 관리
이 전체 파이프라인이 처음부터 끝까지 멀티스레드로 동작하는 것이다.
Virtual Threads: Java 21의 게임 체인저
전통적인 Java 스레드는 OS 스레드와 1:1로 매핑되는 플랫폼 스레드(Platform Thread)다. OS 스레드는 생성 비용이 크고(약 1MB의 스택 메모리), 수천 개 이상 생성하면 컨텍스트 스위칭 오버헤드가 급격히 증가한다. 이것이 스레드풀을 사용하는 근본적인 이유다.
Java 21에서 정식 도입된 Virtual Threads(가상 스레드)는 이 한계를 근본적으로 해결한다. JVM이 관리하는 경량 스레드로, OS 스레드 위에 다수의 가상 스레드를 매핑하는 M:N 스레딩 모델을 사용한다.
// 전통적인 플랫폼 스레드
Thread platformThread = new Thread(() -> {
System.out.println("Platform Thread");
});
// Virtual Thread - 생성 비용이 극도로 낮다
Thread virtualThread = Thread.ofVirtual().start(() -> {
System.out.println("Virtual Thread");
});
// 수백만 개의 Virtual Thread도 가능
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
for (int i = 0; i < 1_000_000; i++) {
executor.submit(() -> {
Thread.sleep(Duration.ofSeconds(1));
return "Done";
});
}
}
Virtual Thread의 핵심은 블로킹 I/O 시 OS 스레드를 점유하지 않는다는 것이다. I/O 대기 상태에 들어가면 JVM이 해당 가상 스레드를 OS 스레드에서 분리(unmount)하고, 다른 가상 스레드를 그 자리에 올린다. 이를 통해 스레드풀 크기의 제약 없이 동시성을 극대화할 수 있다.
Spring Boot 3.2부터는 설정 한 줄로 Tomcat의 요청 처리를 Virtual Thread 기반으로 전환할 수 있다.
spring:
threads:
virtual:
enabled: true
이 설정만으로 기존의 동기 블로킹 코드를 수정하지 않고도 처리량을 대폭 향상시킬 수 있다.
Spring WebFlux: 리액티브 대안
Virtual Threads 이전에 Spring 진영에서 높은 동시성을 달성하기 위한 접근법이 Spring WebFlux였다. Node.js와 유사한 논블로킹 리액티브 모델을 Java/Spring에서 구현한 것이다.
@GetMapping("/users/{id}")
public Mono<User> getUser(@PathVariable String id) {
return userRepository.findById(id); // 논블로킹 반환
}
WebFlux는 Netty 기반으로 동작하며 이벤트 루프 패턴을 사용한다. 적은 스레드로 높은 처리량을 달성할 수 있지만, 리액티브 프로그래밍의 학습 곡선이 가파르고 기존 JDBC 기반 라이브러리와의 호환성 문제가 있었다.
Virtual Threads의 등장으로, 기존의 익숙한 동기 코드 스타일을 유지하면서도 WebFlux에 준하는 동시성을 달성할 수 있게 되었다. 이 때문에 새 프로젝트에서는 Virtual Threads를 먼저 고려하고, 스트리밍이나 배압(backpressure) 제어가 필요한 경우에만 WebFlux를 선택하는 것이 현재의 추세다.
3. Node.js vs Java/Spring: 구조적 비교
Node.js와 Java/Spring은 동시성 처리 방식에서 근본적인 차이를 보인다.
Node.js: 싱글스레드 이벤트 루프
Node.js는 싱글스레드 이벤트 루프 모델을 사용한다. 메인 스레드 하나가 이벤트 루프를 돌면서 들어오는 요청을 처리한다. I/O 작업(파일 읽기, DB 쿼리, 네트워크 요청 등)은 비동기(non-blocking)로 처리되어, I/O 완료 시 콜백이 이벤트 큐에 등록되고 이벤트 루프가 이를 처리한다.

다만 “싱글스레드"라는 표현은 이벤트 루프에 한정된 이야기다. Node.js 내부에는 libuv라는 C 라이브러리가 있고, 파일 시스템 I/O나 DNS 조회 등 OS 레벨에서 비동기를 지원하지 않는 작업은 libuv의 스레드풀(기본 4개)에서 처리된다. 네트워크 I/O는 OS의 epoll/kqueue를 활용하므로 스레드풀을 거치지 않는다. 즉, Node.js는 개발자에게 싱글스레드 모델을 제공하되, 내부적으로는 필요한 곳에 멀티스레드를 활용하는 구조다.
Java/Spring: 멀티스레드풀
Java/Spring은 멀티스레드풀 모델을 사용한다. Tomcat이 관리하는 스레드풀에서 각 요청마다 별도의 스레드를 할당하여 처리한다. 각 스레드는 요청의 시작부터 응답까지 동기적(blocking)으로 처리하는 것이 기본이다.

비교 요약
| 항목 | Node.js | Java/Spring |
|---|---|---|
| 스레딩 모델 | 싱글스레드 이벤트 루프 | 멀티스레드풀 (Tomcat) |
| I/O 처리 | 비동기 논블로킹 | 동기 블로킹 (기본) |
| 동시성 구현 | 이벤트 루프 + 콜백/Promise | 스레드풀 + 동기화 메커니즘 |
| CPU 집약 작업 | 메인 스레드 블로킹 위험 | 별도 스레드에서 병렬 처리 가능 |
| 메모리 사용 | 상대적으로 적음 | 스레드당 메모리 할당 필요 |
| DB 연결 | 비동기 드라이버 | HikariCP 커넥션풀 |
| 확장 방식 | 클러스터 모듈 (프로세스 복제) | 스레드풀 크기 조정 |
각 모델의 장점
Node.js의 강점:
- I/O 바운드 작업에서 높은 처리량
- 적은 메모리로 많은 동시 연결 처리 가능
- 간결한 비동기 코드 (async/await)
- 실시간 애플리케이션(채팅, 스트리밍)에 적합
Java/Spring의 강점:
- CPU 집약적 작업에서 진정한 병렬 처리 가능
- 성숙한 동시성 제어 메커니즘 (synchronized, Lock, Concurrent 패키지)
- 대규모 엔터프라이즈 시스템에서 검증된 안정성
- 스레드 단위의 직관적인 디버깅과 스택 트레이스
대규모의 트래픽 처리는 스프링부트가 가장 잘한다.
이런 말을 자주 듣게 되는 이유가 바로 여기에 있다. JVM의 멀티스레드 지원, Tomcat의 스레드풀, HikariCP의 커넥션풀이 유기적으로 결합하여 높은 처리량과 안정성을 보장하기 때문이다.
4. 마무리
Java는 30년간 “Write Once, Run Anywhere"라는 철학을 지켜왔고, 그 위에 세워진 Spring 생태계는 엔터프라이즈 백엔드의 사실상 표준이 되었다.
이 글에서 다룬 핵심을 정리하면 다음과 같다.
- JVM의 바이트코드 + 멀티스레드 지원이 Java의 근간이다.
- Tomcat 스레드풀이 HTTP 요청을, HikariCP 커넥션풀이 DB I/O를 멀티스레드로 처리하여 Spring Boot의 높은 처리량을 만든다.
- Virtual Threads(Java 21)는 OS 스레드의 한계를 넘어 동시성을 극대화하는 새로운 패러다임이다.
- Node.js의 싱글스레드 이벤트 루프와 Java/Spring의 멀티스레드풀은 각각의 강점이 있으며, 워크로드 특성에 따라 올바른 선택이 달라진다.
기술 선택에 정답은 없다. 중요한 것은 각 기술이 왜 그렇게 설계되었는지를 이해하고, 해결하려는 문제에 맞는 도구를 고르는 것이다.
참고 자료
- [Oracle] Introduction to Java: https://www.oracle.com/java/technologies/introduction-to-java.html
- [Wikipedia] 자바 (프로그래밍 언어): https://ko.wikipedia.org/wiki/자바_(프로그래밍_언어)
- [JetBrains] The State of Developer Ecosystem 2023: https://www.jetbrains.com/lp/devecosystem-2023/
- [velog] 스프링부트는 어떻게 다중 요청을 처리할까?: https://velog.io/@sihyung92/how-does-springboot-handle-multiple-requests
- [velog] Spring-DB커넥션풀과 Hikari CP 알아보기: https://velog.io/@miot2j/Spring-DB커넥션풀과-Hikari-CP-알아보기
- [Gradle] Gradle vs Maven Performance: https://gradle.org/gradle-vs-maven-performance/
- [JEP 444] Virtual Threads: https://openjdk.org/jeps/444
- [Spring Blog] Spring Boot 3.2 Virtual Threads: https://spring.io/blog/2023/09/09/all-together-now-spring-boot-3-2-graalvm-native-images-java-21-and-virtual