Introduction
인프라 관련 세미나에는 항상 참여하는 편인데, 가장 기본이 된 주제가 바로 이 GitOps가 아닌가 싶다. 실제로 시대생팀에서도 GitOps를 통해서 AWS쪽 인프라와 ArgoCD가 바라볼 레포지토리를 정의하는 레포지토리로 인프라를 관리하고 있다.
깃옵스(GitOps)라고 하면 단순히 쿠버네티스 클러스터뿐만 아니라, Terraform이나 Pulumi 혹은 AWS CDK 같은 툴을 통해서 AWS에도 적용할 수 있다. 이러다 보니 인프라를 담당하는 두 개의 큰 축을 모두 깃옵스로 구현할 수 있다. 대부분의 기업에서도 클러스터를 담당하는 부분과 클라우드를 담당하는 부분을 나눠서 관리하고 있다.
개인적으로도 GitOps라는 키워드가 매우 인기 있는 키워드라고 생각한다. 이것보다 더 DevOps쪽 분야에서 최신 키워드는 플랫폼 엔지니어링 정도가 아닐까 싶다. GitOps 베이스에서 더 나아가 몇몇 기업들은 Terraform이나 ArgoCD 같은 툴이 아니라, 직접 비슷한 툴을 만들어 운영하면서 좀 더 플랫폼 엔지니어링을 통해 안전하고 편리한 플랫폼을 구축하는 것 같다.
GitOps란 무엇인가
GitOps의 정의는 매우 간단하다. Git 레포지토리를 인프라와 애플리케이션의 Single Source of Truth(SSOT)로 사용하는 운영 모델이다. 개발자에게 친숙한 Git을 통해서 인프라를 관리하는 것이다.
Git 레포지토리를 SSOT로 본다는 것에는 엄청나게 많고 중요한 의미가 담겨 있는데, 바로 아래와 같다. CNCF의 OpenGitOps 프로젝트에서 정의한 공식 원칙이 4가지 있다.
4가지 핵심 원칙
- Declarative(선언적): 시스템의 원하는 상태(Desired State)를 선언적으로 기술한다. Kubernetes 매니페스트, Kustomize overlay, Helm chart가 이에 해당한다. 어떻게(How)가 아니라 무엇(What)을 정의하는 것이다.
- Versioned and Immutable(버전 관리 및 불변성): 모든 상태가 Git에 저장되므로 자연스럽게 버전 관리, 감사 추적(audit trail) 그리고 롤백이 가능하다. 누가 언제 왜 변경했는지 Git History로 추적할 수 있어서 보안 감사 대응에도 유리하다.
- Pulled Automatically(자동 Pull): 승인된 변경 사항이 Git에 머지되면 에이전트가 자동으로 이를 감지하고 클러스터에 적용한다. ArgoCD나 Flux가 이 역할을 한다.
- Continuously Reconciled(지속적 조정): 에이전트가 실제 상태(Live State)와 원하는 상태(Desired State)를 지속적으로 비교하고, 차이가 발생하면 자동으로 교정한다. 누군가 kubectl edit나 AWS Console을 통해 직접 변경해도 ArgoCD나 자동화된 IaC가 다시 원래 상태로 되돌리게 된다.
위와 같이 4가지의 핵심 원칙이 있다. 워낙 많은 GitOps에 대해 포스팅된 글들이 위 내용을 많이 인용하고 있으나, 이해를 돕기 위해 상세하게 작성하면 아래와 같다.
선언형 패러다임
GitOps의 첫 번째가 되는 개념은 선언형(Declarative)이라는 것이다. 선언적이라는 개념을 이해하기 위해서는 반대의 개념인 명령형(Imperative)과 비교해보면 된다.
선언형은 쿠버네티스 클러스터나 Terraform으로 S3와 같은 리소스를 생성하는 것과 마찬가지로, 어떤 리소스를 선언할 것인지만 적어두고, 어떤 식으로 생성되는지에 대해서는 관심을 두지 않는다. 상세한 구현은 Terraform Provider나 Kubernetes Cluster의 역할이기 때문이다. 단적으로 실제 스크립트들을 보면 다음과 같다.
Terraform으로 S3 버킷을 생성하는 선언형 스크립트:
resource "aws_s3_bucket" "app_assets" {
bucket = "my-app-assets"
tags = {
Team = "backend"
}
}
resource "aws_s3_bucket_versioning" "app_assets" {
bucket = aws_s3_bucket.app_assets.id
versioning_configuration {
status = "Enabled"
}
}
Kubernetes로 nginx Deployment를 선언하는 매니페스트:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.27
ports:
- containerPort: 80
두 예시 모두 “3개의 nginx 파드를 띄워라”, “S3 버킷을 만들어라"라는 원하는 상태만 기술할 뿐, 구체적인 생성 절차는 Terraform Provider와 Kubernetes 컨트롤러가 알아서 처리한다.
반면 같은 작업을 명령형(CLI)으로 수행하면 다음과 같다.
AWS CLI로 S3 버킷을 생성하는 명령형 스크립트:
aws s3api create-bucket \
--bucket my-app-assets \
--region ap-northeast-2 \
--create-bucket-configuration LocationConstraint=ap-northeast-2
aws s3api put-bucket-versioning \
--bucket my-app-assets \
--versioning-configuration Status=Enabled
aws s3api put-bucket-tagging \
--bucket my-app-assets \
--tagging 'TagSet=[{Key=Team,Value=backend}]'
kubectl로 nginx Deployment를 생성하는 명령형 스크립트:
kubectl create deployment nginx --image=nginx:1.27 --replicas=3
kubectl expose deployment nginx --port=80 --target-port=80
언뜻 보면 명령형이 더 간결해 보이지만, 실제 운영에서는 치명적인 단점들이 있다.
- 멱등성이 없다: 같은 스크립트를 두 번 실행하면 “이미 존재합니다” 에러가 발생한다. 선언형은 현재 상태와 원하는 상태를 비교해서 차이만 적용하므로 몇 번을 실행해도 동일한 결과를 보장한다.
- 상태 추적이 불가능하다: 스크립트는 실행한 순간의 행위만 기록할 뿐, 현재 인프라가 어떤 상태인지 알 수 없다. 누군가 콘솔에서 직접 설정을 변경하면 스크립트와 실제 상태가 즉시 괴리된다.
- 변경 이력 관리가 어렵다: 셸 스크립트를 Git에 넣어도 “어떤 명령을 실행했는가"만 알 수 있을 뿐, “현재 인프라가 어떤 상태여야 하는가"를 파악하기 어렵다.
- 롤백이 복잡하다: 이전 상태로 되돌리려면 역방향 스크립트를 별도로 작성해야 한다. 선언형은 이전 커밋으로
git revert하면 에이전트가 자동으로 이전 상태를 복원한다.
위와 같이 리소스를 선언형으로 구현하느냐 명령형으로 구현하느냐에 대한 차이는 크다. 따라서 많은 CNCF의 프로젝트나 세미나에서도 GitOps 기반의 선언형 인프라 관리를 채택하는 방식으로 사용하고 있다.
버전 관리 및 불변성
버전 관리 및 불변성에 대한 부분은 사실 Git의 개념을 그대로 가져온다. 어떤 부분이 어떻게 변화되었는지 git diff를 통해서 확인할 수 있으며, 어떤 사람이 어떤 커밋 메시지를 통해서 변경했는지 파악이 가능하다.
롤백(Rollback) 또한 복잡하고 신중하게 이전에 작업했던 S3 생성을 순서대로 지켜서 지우는 것이 아니라, 단순히 git revert를 통해서 해결할 수 있다.
예를 들어 AWS에서 누가 어떤 리소스에 접근하고 변경했는지 추적하려면 CloudTrail을 사용해야 한다. CloudTrail의 이벤트 로그는 다음과 같은 JSON 형태로 기록된다.
{
"eventTime": "2026-03-15T09:23:17Z",
"eventName": "PutBucketVersioning",
"userIdentity": {
"type": "IAMUser",
"userName": "deploy-bot"
},
"requestParameters": {
"bucketName": "my-app-assets",
"VersioningConfiguration": {
"Status": "Enabled"
}
}
}
“누가 언제 API를 호출했는가"는 알 수 있지만, 왜 변경했는가는 알 수 없다. 변경 전후 상태를 비교하려면 AWS Config 같은 별도 서비스를 추가로 설정해야 하고, JSON 로그를 일일이 뒤져야 하므로 가독성도 떨어진다.
반면 GitOps 기반에서는 Git이 곧 감사 로그가 된다. 커밋 히스토리만 봐도 인프라 변경 이력이 한눈에 읽힌다.
$ git log --oneline
a1b2c3d feat: increase nginx replicas to 5 for traffic spike
e4f5g6h fix: rollback S3 bucket policy to restrict public access
i7j8k9l feat: add redis cluster for session caching
git diff로 변경 전후 상태를 즉시 비교할 수 있고, git blame으로 특정 라인을 누가 언제 변경했는지 추적할 수 있다. 더 나아가 GitHub PR 단위로 “왜” 변경했는지 description과 리뷰 코멘트가 함께 남기 때문에, CloudTrail에서는 얻을 수 없는 변경의 맥락과 의도까지 기록된다.
자동 Pull
GitOps를 통해서 배포하는 경우에는 일반적으로 Push 방식이 아니라 Pull 방식을 사용한다. AWS에서 제공하는 매니지드 컨테이너 서비스인 ECS에 배포하는 경우를 보면, 일반적으로는 다음과 같은 GitHub Actions 워크플로우를 통해서 배포한다.
name: Deploy to ECS
on:
push:
branches: [main]
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v4
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ap-northeast-2
- name: Login to Amazon ECR
id: login-ecr
uses: aws-actions/amazon-ecr-login@v2
- name: Build and push Docker image
env:
ECR_REGISTRY: ${{ steps.login-ecr.outputs.registry }}
IMAGE_TAG: ${{ github.sha }}
run: |
docker build -t $ECR_REGISTRY/my-app:$IMAGE_TAG .
docker push $ECR_REGISTRY/my-app:$IMAGE_TAG
- name: Deploy to ECS
uses: aws-actions/amazon-ecs-deploy-task-definition@v2
with:
task-definition: task-definition.json
service: my-app-service
cluster: my-app-cluster
wait-for-service-stability: true
이러한 방식은 Push 방식이라고 부른다. CI 파이프라인이 빌드부터 배포까지 모든 과정을 직접 수행하며, 외부에서 대상 환경으로 변경 사항을 밀어넣는(Push) 구조다. 즉 GitHub Actions가 AWS 자격 증명을 가지고 직접 ECS에 접근하여 배포를 실행한다.
ArgoCD와 같은 경우에는 Pull 방식을 사용하는데, 쿠버네티스 클러스터 안에서 동작하는 ArgoCD가 특정 깃허브 레포지토리를 바라보면서, 주기적으로 sync를 맞추는 방식을 통해서 직접 source를 가져와서(Pull) 사용한다. CI 파이프라인은 이미지 빌드와 매니페스트 업데이트까지만 담당하고, 실제 클러스터 배포는 ArgoCD가 알아서 처리한다.
Push와 Pull 방식의 장단점을 나타내면 다음과 같다.
| Push 방식 | Pull 방식 | |
|---|---|---|
| 배포 주체 | CI 파이프라인 (외부) | 클러스터 내부 에이전트 |
| 자격 증명 | CI에 클러스터/클라우드 접근 권한 필요 | 에이전트가 Git만 읽으면 됨 |
| 보안 | 외부에 민감한 자격 증명 노출 위험 | 클러스터 밖으로 자격 증명이 나가지 않음 |
| 드리프트 감지 | 불가능 (배포 시점에만 동작) | 지속적으로 상태 비교 및 자동 교정 |
| 구현 난이도 | 낮음 (익숙한 CI/CD 파이프라인) | 중간 (ArgoCD/Flux 설치 및 설정 필요) |
지속적 조정
마지막으로는 지속적인 조정이 있다. 위에서 다뤘던 내용의 종합이며, GitOps 레포지토리를 상태로 사용한다는 점이다. Git이 이전 버전과 diff를 통해서 어떤 점이 바뀌었는지 확인하듯이, ArgoCD나 Terraform 같은 IaC는 현재 상태와 GitOps를 통해서 선언적으로 명시되어 있는 내용을 적용했을 때의 상태를 비교하여 변화 여부를 체크한다.
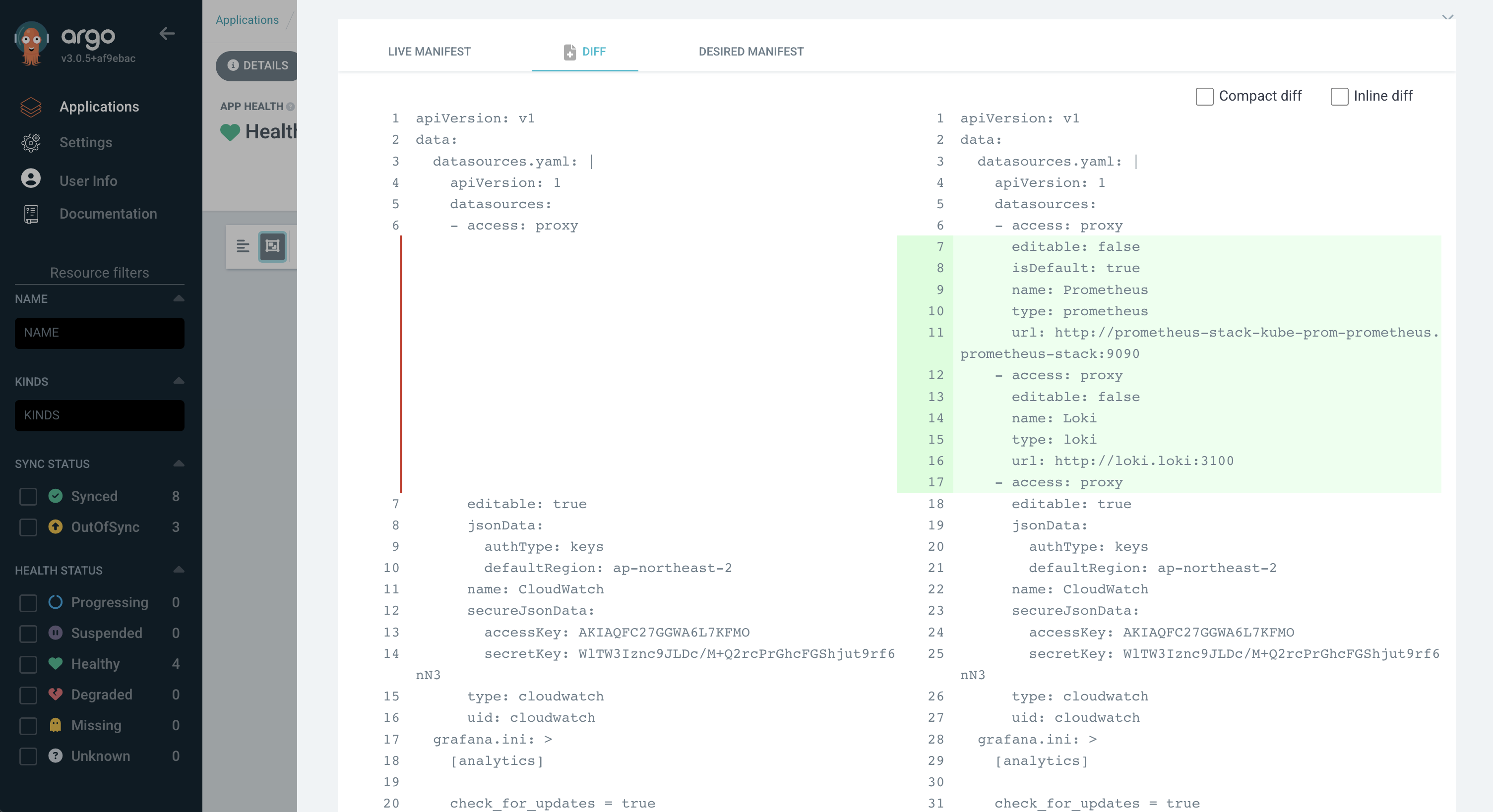
ArgoCD에서는 LIVE MANIFEST와 DESIRED MANIFEST라는 이름으로 변화 여부를 체크한다. LIVE는 현재 쿠버네티스 클러스터의 상태를 의미하며, DESIRED는 GitOps 레포지토리 내용에 따라서 쿠버네티스 클러스터가 바라는 상태를 의미한다.
위 이미지는 Prometheus나 Loki를 datasource로 사용하도록 설정하였고, 따로 Sync를 맞추지 않아서 바라는 상태와 멀어졌기 때문에 어떤 부분이 차이점(diff)으로 남는지 확인할 수 있다.
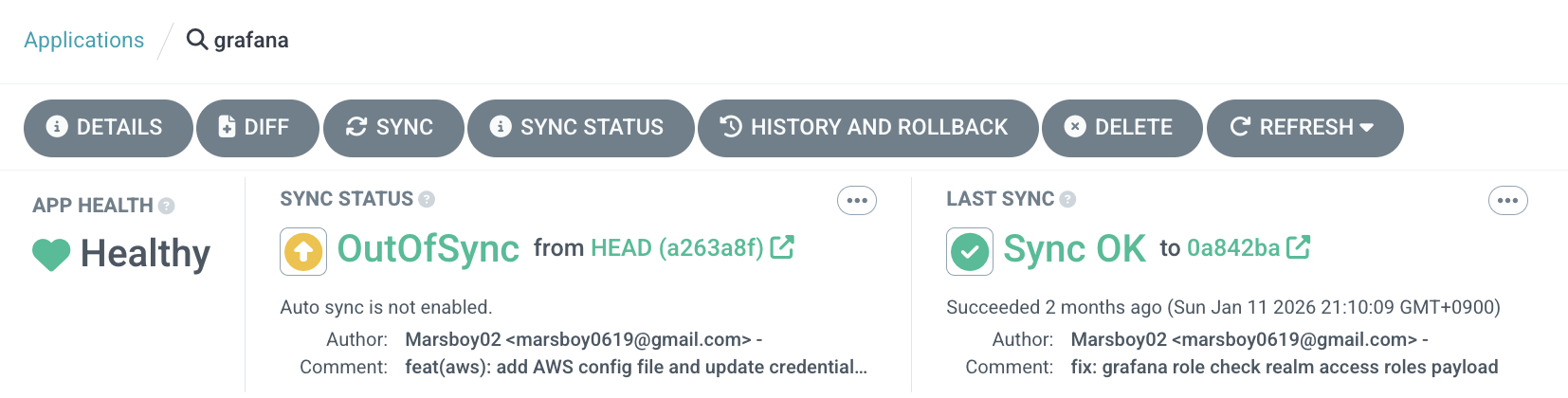
위와 같이 마지막 Sync를 맞춘 시점이 2달 이전이며, 현재 상태는 마지막 커밋을 기준으로 변경되었으니 Sync를 통해서 GitOps 레포지토리 상태를 기준으로 설정할 수 있다. 따로 Auto-Sync를 적용하지 않은 ArgoCD Application이기 때문에 위와 같이 OutOfSync 상태가 보이는 것이다.
만약 Auto-Sync를 설정해놓는 경우, 일반적인 CI/CD 파이프라인 모델과 비슷하게 특정 서비스를 GitOps 레포지토리에 Push하면 파이프라인을 거쳐 배포되는 것까지의 과정이 비슷하다. 하지만 내부적으로는 Push 방식이 아닌 Pull 방식을 쓰게 되며, 구현 난이도는 높지만 보안이나 자격 증명에 있어서 이점을 얻게 된다.
기존 CI/CD와 GitOps의 차이
Push vs Pull 방식의 차이는 위에서 충분히 다뤘으니, 여기서는 전통적 CI/CD 파이프라인과 GitOps가 근본적으로 무엇이 다른지에 집중해보자.
배포의 주도권: 파이프라인 vs 선언적 상태
전통적 CI/CD에서는 파이프라인이 배포의 전 과정을 주도한다. Jenkins, GitHub Actions, GitLab CI 같은 도구가 코드 빌드, 테스트, 이미지 푸시, 배포 스크립트 실행까지 하나의 파이프라인 안에서 순차적으로 처리한다. 배포란 곧 “파이프라인의 마지막 스텝을 성공적으로 실행하는 것"이다.
[전통적 CI/CD]
코드 Push → CI 빌드 → 테스트 → 이미지 빌드 → 배포 스크립트 실행 → 완료
(하나의 파이프라인이 모든 것을 담당)
[GitOps]
코드 Push → CI 빌드 → 테스트 → 이미지 빌드 → 매니페스트 업데이트 (여기까지 CI)
↓
GitOps 에이전트가 감지 → 클러스터 적용 (여기서부터 CD)
GitOps에서는 CI와 CD가 명확하게 분리된다. CI 파이프라인은 이미지를 빌드하고 GitOps 레포지토리의 매니페스트를 업데이트하는 것까지만 담당한다. 실제 클러스터에 반영하는 CD는 ArgoCD나 Flux 같은 에이전트의 몫이다.
환경의 상태를 누가 알고 있는가
이것이 가장 본질적인 차이다. 전통적 CI/CD에서는 배포가 성공했는지 파이프라인의 exit code로만 판단한다. 배포 이후 누군가 kubectl edit으로 직접 리소스를 수정하거나, AWS Console에서 설정을 변경해도 파이프라인은 이를 알 수 없다. 다음 배포가 트리거되기 전까지는 실제 환경이 어떤 상태인지 아무도 보장하지 못한다.
GitOps에서는 에이전트가 지속적으로 실제 상태와 원하는 상태를 비교한다. 누군가 수동으로 변경하더라도 에이전트가 이를 감지하고 원래 상태로 되돌린다. 즉 환경의 상태가 항상 Git 레포지토리와 일치한다는 것을 보장할 수 있다.
장애 복구와 롤백
전통적 CI/CD에서 롤백이란 “이전 버전의 배포 파이프라인을 다시 실행하는 것"이다. 이전 빌드 아티팩트가 남아있어야 하고, 배포 스크립트가 멱등하게 작성되어 있어야 하며, 경우에 따라 데이터베이스 마이그레이션 같은 부수 효과도 고려해야 한다.
GitOps에서의 롤백은 git revert 한 줄이다. Git 히스토리에 원하는 상태가 모두 기록되어 있으므로, 이전 커밋으로 되돌리면 에이전트가 자동으로 클러스터를 해당 상태로 복원한다. 파이프라인을 다시 실행할 필요도 없고, 이전 아티팩트를 찾을 필요도 없다.
멀티 환경 관리
전통적 CI/CD에서 dev, staging, production 같은 멀티 환경을 관리하려면 파이프라인마다 환경별 변수와 분기 로직을 넣어야 한다. 환경이 늘어날수록 파이프라인은 복잡해지고, 환경 간 설정 차이를 파악하려면 파이프라인 코드를 읽어야 한다.
GitOps에서는 환경별로 디렉토리나 브랜치를 나누면 된다. Kustomize overlay나 Helm values 파일로 환경 간 차이를 선언적으로 관리할 수 있고, diff만으로 dev와 production의 설정 차이를 한눈에 확인할 수 있다.
gitops-repo/
├── base/
│ ├── deployment.yaml
│ └── kustomization.yaml
├── overlays/
│ ├── dev/
│ │ └── kustomization.yaml # replicas: 1, resources 최소
│ ├── staging/
│ │ └── kustomization.yaml # replicas: 2, dev와 유사
│ └── production/
│ └── kustomization.yaml # replicas: 5, resources 확대, HPA 설정
감사와 컴플라이언스
전통적 CI/CD에서 “누가 언제 무엇을 배포했는가"를 추적하려면 CI 도구의 빌드 로그, 배포 로그, 그리고 CloudTrail 같은 감사 도구를 조합해야 한다. 도구마다 로그 형식이 다르고 보존 기간도 제각각이다.
GitOps에서는 Git 자체가 완전한 감사 로그다. 모든 변경은 커밋으로 기록되고, PR 리뷰를 거쳐 승인된 변경만 머지되므로 “누가, 언제, 왜, 무엇을” 변경했는지가 하나의 도구 안에서 완결된다. SOC 2나 ISO 27001 같은 컴플라이언스 요구사항 대응에도 Git 히스토리 하나로 충분하다.
GitOps 실전 적용 패턴
GitOps를 실제로 도입할 때 가장 먼저 마주치는 질문은 “레포지토리를 어떻게 구성할 것인가"이다. 이 결정이 이후의 배포 워크플로우, 팀 간 협업, 그리고 보안 경계까지 좌우하기 때문에 신중하게 선택해야 한다.
레포지토리 구조 전략: 모노레포 vs 멀티레포
GitOps 레포지토리 구성은 크게 두 가지 전략으로 나뉜다.
모노레포(Monorepo) 는 애플리케이션 코드와 인프라 매니페스트를 하나의 레포지토리에서 관리하는 방식이다.
my-service/
├── src/ # 애플리케이션 소스 코드
│ ├── main.go
│ └── ...
├── Dockerfile
├── .github/workflows/ci.yaml # CI 파이프라인
└── k8s/ # 쿠버네티스 매니페스트
├── base/
│ ├── deployment.yaml
│ ├── service.yaml
│ └── kustomization.yaml
└── overlays/
├── dev/
└── prod/
모노레포의 장점은 개발자 입장에서 직관적이라는 것이다. 코드와 배포 설정이 같은 레포지토리에 있으므로 PR 하나로 기능 추가와 배포 설정 변경을 함께 리뷰할 수 있다. 하지만 단점도 명확하다. 애플리케이션 코드가 변경될 때마다 ArgoCD가 매니페스트 변경을 감지하려고 불필요하게 동작할 수 있고, 인프라 접근 권한과 애플리케이션 코드 접근 권한을 분리하기 어렵다.
멀티레포(Polyrepo) 는 애플리케이션 코드와 GitOps 매니페스트를 별도의 레포지토리로 분리하는 방식이다.
# 레포지토리 1: my-service (애플리케이션)
my-service/
├── src/
├── Dockerfile
└── .github/workflows/ci.yaml # 빌드 후 GitOps 레포에 매니페스트 업데이트
# 레포지토리 2: gitops-manifests (인프라)
gitops-manifests/
├── my-service/
│ ├── base/
│ │ ├── deployment.yaml
│ │ ├── service.yaml
│ │ └── kustomization.yaml
│ └── overlays/
│ ├── dev/
│ ├── staging/
│ └── prod/
├── another-service/
│ ├── base/
│ └── overlays/
└── addons/
├── argocd/
├── monitoring/
└── ingress-controller/
대부분의 프로덕션 환경에서는 멀티레포를 채택한다. CI 파이프라인은 애플리케이션 레포지토리에서 이미지를 빌드하고, 완료되면 GitOps 레포지토리의 이미지 태그만 업데이트한다. ArgoCD는 GitOps 레포지토리만 바라보면 되므로 관심사가 깔끔하게 분리된다. 또한 인프라 레포지토리에 대한 접근 권한을 DevOps 팀에게만 부여하는 식으로 보안 경계를 나눌 수 있다.
실제로 시대생팀에서도 이 멀티레포 구조를 사용하고 있다. AWS 인프라를 관리하는 Terraform 레포지토리와 쿠버네티스 클러스터의 매니페스트를 관리하는 GitOps 레포지토리를 분리하여 운영한다.
환경별 배포 관리
GitOps에서 멀티 환경을 관리하는 방법은 크게 디렉토리 기반과 브랜치 기반 두 가지가 있다.
디렉토리 기반은 하나의 브랜치(보통 main) 안에서 환경별로 디렉토리를 나누는 방식이다. ArgoCD의 공식 문서에서도 이 방식을 권장한다.
# ArgoCD Application - dev 환경
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: my-service-dev
spec:
source:
repoURL: https://github.com/org/gitops-manifests
path: my-service/overlays/dev # 디렉토리로 환경 구분
targetRevision: main
destination:
server: https://dev-cluster.example.com
namespace: my-service
# ArgoCD Application - prod 환경
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: my-service-prod
spec:
source:
repoURL: https://github.com/org/gitops-manifests
path: my-service/overlays/prod # 같은 브랜치, 다른 디렉토리
targetRevision: main
destination:
server: https://prod-cluster.example.com
namespace: my-service
디렉토리 기반의 장점은 환경 간 차이를 diff로 즉시 비교할 수 있다는 것이다. diff overlays/dev overlays/prod 한 줄이면 두 환경의 설정 차이를 한눈에 파악할 수 있다.
브랜치 기반은 main, staging, dev 등 브랜치별로 환경을 나누는 방식이다. Git 브랜치 전략에 익숙한 팀에게는 자연스러울 수 있지만, 환경 간 차이를 파악하려면 브랜치를 넘나들며 비교해야 하고, 브랜치 머지 충돌이 발생할 수 있어 운영이 복잡해진다. 이런 이유로 실무에서는 디렉토리 기반을 더 많이 사용한다.
Kustomize vs Helm
GitOps 매니페스트를 관리하는 도구로는 Kustomize와 Helm이 대표적이다. 두 도구는 접근 방식이 근본적으로 다르다.
Kustomize는 기본 YAML을 그대로 두고, 환경별 차이점만 패치로 덮어쓰는 방식이다. 템플릿 없이 순수한 쿠버네티스 YAML을 유지할 수 있다는 것이 핵심이다.
# base/deployment.yaml - 순수한 쿠버네티스 YAML
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-service
spec:
replicas: 1
template:
spec:
containers:
- name: my-service
image: my-service:latest
resources:
requests:
cpu: 100m
memory: 128Mi
# overlays/prod/kustomization.yaml - 프로덕션 패치
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
resources:
- ../../base
patches:
- target:
kind: Deployment
name: my-service
patch: |-
- op: replace
path: /spec/replicas
value: 5
- op: replace
path: /spec/template/spec/containers/0/resources/requests/cpu
value: 500m
- op: replace
path: /spec/template/spec/containers/0/resources/requests/memory
value: 512Mi
Helm은 Go 템플릿 엔진을 사용하여 values 파일의 값을 주입하는 방식이다. 복잡한 조건 분기나 반복이 필요한 경우에 유리하다.
# templates/deployment.yaml - Go 템플릿
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Release.Name }}
spec:
replicas: {{ .Values.replicas }}
template:
spec:
containers:
- name: {{ .Release.Name }}
image: "{{ .Values.image.repository }}:{{ .Values.image.tag }}"
resources:
requests:
cpu: {{ .Values.resources.requests.cpu }}
memory: {{ .Values.resources.requests.memory }}
# values-prod.yaml
replicas: 5
image:
repository: my-service
tag: v1.2.3
resources:
requests:
cpu: 500m
memory: 512Mi
| Kustomize | Helm | |
|---|---|---|
| 방식 | 패치(오버레이) | 템플릿(값 주입) |
| 학습 곡선 | 낮음 (순수 YAML) | 중간 (Go 템플릿 문법) |
| 유연성 | 단순한 오버라이드에 적합 | 복잡한 조건 분기, 반복 가능 |
| 가독성 | base YAML이 그대로 유효 | 템플릿 렌더링 전에는 읽기 어려움 |
| 패키지 배포 | 지원하지 않음 | Chart로 패키징하여 배포 가능 |
| 커뮤니티 차트 | 없음 | 풍부한 공식/커뮤니티 차트 |
실무에서는 둘 중 하나만 쓰기보다, 자체 서비스의 매니페스트는 Kustomize로, 써드파티 도구(Prometheus, Grafana, Ingress Controller 등)는 Helm Chart로 관리하는 조합이 일반적이다. ArgoCD도 Kustomize와 Helm을 모두 네이티브로 지원하기 때문에 하나의 GitOps 레포지토리 안에서 두 방식을 혼용할 수 있다.
GitOps 도입 시 주의할 점
GitOps가 만능은 아니다. 도입 과정에서 간과하기 쉬운 함정들이 있고, 이를 미리 인지하지 못하면 오히려 운영 복잡도만 높아질 수 있다.
Secret 관리
GitOps의 가장 큰 약점은 Secret 관리다. Git 레포지토리를 Single Source of Truth로 사용한다는 것은 모든 상태를 Git에 저장한다는 뜻인데, 데이터베이스 비밀번호나 API 키 같은 민감한 정보를 평문으로 Git에 커밋하는 것은 절대 해서는 안 된다. 한 번이라도 커밋된 시크릿은 Git 히스토리에 영원히 남기 때문에 git revert로도 완전히 제거할 수 없다.
이 문제를 해결하기 위한 도구들이 여러 가지 존재한다.
Sealed Secrets는 Bitnami에서 만든 도구로, 클러스터에 설치된 컨트롤러만 복호화할 수 있는 암호화된 시크릿을 Git에 저장하는 방식이다.
apiVersion: bitnami.com/v1alpha1
kind: SealedSecret
metadata:
name: database-credentials
spec:
encryptedData:
password: AgBy3i4OJSWK+PiTySYZZA9rO... # 암호화된 값
username: AgCtr8OJSWK+UiWySYZZA7pQ...
External Secrets Operator는 AWS Secrets Manager, HashiCorp Vault, GCP Secret Manager 같은 외부 시크릿 저장소에서 값을 가져와 쿠버네티스 Secret으로 자동 생성하는 방식이다. Git에는 “어디서 시크릿을 가져올지"에 대한 참조만 저장되므로 민감한 값이 레포지토리에 노출되지 않는다.
apiVersion: external-secrets.io/v1beta1
kind: ExternalSecret
metadata:
name: database-credentials
spec:
refreshInterval: 1h
secretStoreRef:
name: aws-secrets-manager
kind: ClusterSecretStore
target:
name: database-credentials
data:
- secretKey: password
remoteRef:
key: prod/my-service/db-password # AWS Secrets Manager의 경로
- secretKey: username
remoteRef:
key: prod/my-service/db-username
SOPS (Secrets OPerationS)는 Mozilla에서 만든 도구로, YAML 파일의 값(value)만 선택적으로 암호화하고 키(key)는 평문으로 유지하는 방식이다. ArgoCD에서 SOPS 플러그인을 통해 네이티브로 지원한다.
apiVersion: v1
kind: Secret
metadata:
name: database-credentials
data:
password: ENC[AES256_GCM,data:cG1c...,type:str] # 값만 암호화
username: ENC[AES256_GCM,data:YWRt...,type:str]
sops:
kms:
- arn: arn:aws:kms:ap-northeast-2:123456789:key/abcd-1234
팀의 규모와 보안 요구사항에 따라 선택이 달라지겠지만, 클라우드 환경에서는 External Secrets Operator가 가장 널리 사용되고 있다. 이미 AWS Secrets Manager나 Vault를 사용하고 있다면 기존 시크릿 관리 체계를 그대로 활용할 수 있기 때문이다.
롤백 전략
앞서 GitOps에서의 롤백은 git revert라고 설명했지만, 실제로는 그렇게 단순하지 않은 경우가 많다.
가장 흔한 문제는 데이터베이스 마이그레이션과의 충돌이다. 애플리케이션 코드를 이전 버전으로 되돌려도, 이미 실행된 DB 마이그레이션은 되돌아가지 않는다. 새로운 컬럼을 추가하는 마이그레이션이 적용된 후 롤백하면, 이전 버전의 코드가 새로운 스키마와 호환되지 않을 수 있다. 따라서 마이그레이션은 항상 하위 호환성(backward compatible)을 유지하도록 작성해야 한다.
또 다른 문제는 여러 서비스 간의 의존성이다. 서비스 A의 매니페스트를 롤백했는데, 서비스 A가 의존하는 서비스 B의 API가 이미 변경되어 있다면 롤백이 오히려 장애를 유발할 수 있다. 이런 상황을 방지하기 위해 서비스 간 API 버전 관리와 하위 호환성 정책을 함께 가져가야 한다.
ArgoCD에서는 롤백을 두 가지 방식으로 수행할 수 있다.
- Git 기반 롤백:
git revert로 매니페스트를 이전 상태로 되돌린다. Git 히스토리에 롤백 이력이 남으므로 감사 추적에 유리하다. 이 방식이 GitOps 원칙에 부합하는 정석적인 방법이다. - ArgoCD UI 기반 롤백: ArgoCD 대시보드에서 이전 배포 히스토리를 선택하여 즉시 롤백할 수 있다. 긴급 상황에서 빠르게 대응할 수 있지만, Git과 실제 상태가 일시적으로 불일치하게 된다. 장애 대응 후 반드시 Git에도 해당 변경을 반영해야 한다.
대규모 조직에서의 운영
GitOps를 소규모 팀에서 도입하는 것과 수십 개의 서비스를 운영하는 대규모 조직에서 도입하는 것은 완전히 다른 이야기다.
ApplicationSet은 ArgoCD에서 대규모 환경을 관리하기 위해 제공하는 기능이다. 서비스마다 ArgoCD Application을 하나하나 수동으로 만드는 대신, 패턴을 정의하면 자동으로 Application을 생성해준다.
apiVersion: argoproj.io/v1alpha1
kind: ApplicationSet
metadata:
name: all-services
spec:
generators:
- git:
repoURL: https://github.com/org/gitops-manifests
revision: main
directories:
- path: "*/overlays/prod" # 모든 서비스의 prod 환경을 자동 감지
template:
metadata:
name: "{{path[0]}}-prod"
spec:
source:
repoURL: https://github.com/org/gitops-manifests
path: "{{path}}"
targetRevision: main
destination:
server: https://prod-cluster.example.com
namespace: "{{path[0]}}"
위 설정만으로 GitOps 레포지토리에 새로운 서비스 디렉토리를 추가하면, ArgoCD Application이 자동으로 생성된다. 서비스가 10개든 100개든 ApplicationSet 하나로 관리할 수 있다.
PR 기반 배포 승인도 대규모 조직에서는 중요하다. GitOps 레포지토리의 main 브랜치에 직접 푸시하는 것이 아니라, PR을 통해 변경 사항을 리뷰하고 승인한 후에만 머지되도록 브랜치 보호 규칙을 설정해야 한다. GitHub의 CODEOWNERS 파일을 활용하면 특정 환경(예: production)의 매니페스트 변경 시 반드시 DevOps 팀의 승인을 받도록 강제할 수 있다.
# CODEOWNERS
/*/overlays/prod/ @org/devops-team # prod 환경 변경은 DevOps 팀 승인 필수
/*/overlays/dev/ @org/developers # dev 환경은 개발팀이 자율적으로 관리
/addons/ @org/platform-team # 클러스터 애드온은 플랫폼 팀 담당
마지막으로 알림과 모니터링이다. ArgoCD는 Slack, Teams 등과 연동하여 sync 상태 변경, 배포 성공/실패 알림을 보낼 수 있다. 서비스가 많아질수록 어떤 서비스가 OutOfSync 상태인지, 어떤 배포가 실패했는지를 자동으로 알려주는 체계가 필수적이다. ArgoCD Notifications를 통해 이를 설정할 수 있으며, Prometheus 메트릭을 통해 Grafana 대시보드에서 전체 배포 현황을 모니터링할 수도 있다.
Conclusion
이 글에서는 GitOps의 핵심 원칙부터 실전 적용 패턴, 그리고 도입 시 주의할 점까지 폭넓게 다뤄보았다.
정리하면, GitOps는 Git 레포지토리를 인프라와 애플리케이션의 Single Source of Truth로 삼는 운영 모델이다. 선언적 인프라 정의, 버전 관리와 불변성, Pull 기반 자동 배포, 그리고 지속적 조정이라는 4가지 핵심 원칙을 통해 전통적 CI/CD에서 해결하기 어려웠던 문제들 — 환경 상태 추적, 감사 로그, 드리프트 감지, 안전한 롤백 — 을 구조적으로 해결한다.
실전에서는 모노레포와 멀티레포 중 팀 상황에 맞는 레포지토리 전략을 선택하고, Kustomize와 Helm을 적절히 조합하여 매니페스트를 관리하며, Secret 관리와 롤백 전략 같은 현실적인 문제에도 대비해야 한다.
개인적으로 GitOps는 단순한 배포 도구나 방법론을 넘어서, 현대 DevOps 문화의 중심 축이 되어가고 있다고 생각한다. 인프라를 코드로 관리하고, 변경 사항을 리뷰하고, 승인된 변경만 자동으로 반영하는 이 흐름은 결국 소프트웨어 엔지니어링의 원칙을 인프라 운영에도 동일하게 적용하자는 DevOps의 본질과 맞닿아 있다. 실제로 CNCF 생태계의 주요 프로젝트들이 GitOps를 전제로 설계되고 있고, 많은 기업들이 GitOps를 기반으로 플랫폼 엔지니어링까지 확장해 나가고 있다.
아직 GitOps를 도입하지 않았다면, 작은 프로젝트 하나부터 시작해보는 것을 추천한다. Kustomize로 매니페스트를 구성하고, ArgoCD를 설치하고, Git에 푸시하면 클러스터에 반영되는 그 경험을 한 번 해보면 — 다시 수동 배포로 돌아가기는 어려울 것이다.