「接続はできているのに、ヘルスチェックだけが失敗する。」
オンプレミスのK3sクラスターからTailscale VPN経由でAWS ElastiCache(Redis)に接続する構成において、デプロイ直後にPodがReady状態に遷移しないという問題に遭遇した。Redis接続自体は成功しており、簡単なコマンド(HELLO、CLIENT)には正常なレスポンスが返ってくるのに、ヘルスチェックで使用されるINFOコマンドのレスポンスだけが消えるという奇妙な現象だった。
結論から言うと、この問題の原因は**MTU(Maximum Transmission Unit)**だった。小さなパケットはVPNトンネルを問題なく通過するが、大きなパケットはカプセル化後に物理NICのMTUを超えてドロップされる典型的な症状だった。
実はMTUについては名前を聞いたことはあっても、実際に遭遇するとは思っていなかったため、最初はパケットサイズによってレスポンスが変わるという点に気づかなかった。単純にトラフィックが流れていないと思い込み、ノードレベルとPodレベルでpingとDNS名前解決を繰り返し確認することに時間を費やしてしまった。
この記事では、トラブルシューティングのプロセスとともに、MTUとMSSの概念を整理し、最終的にMSS ClampingとFlannel MTU設定で問題を解決するまでの過程を解説する。
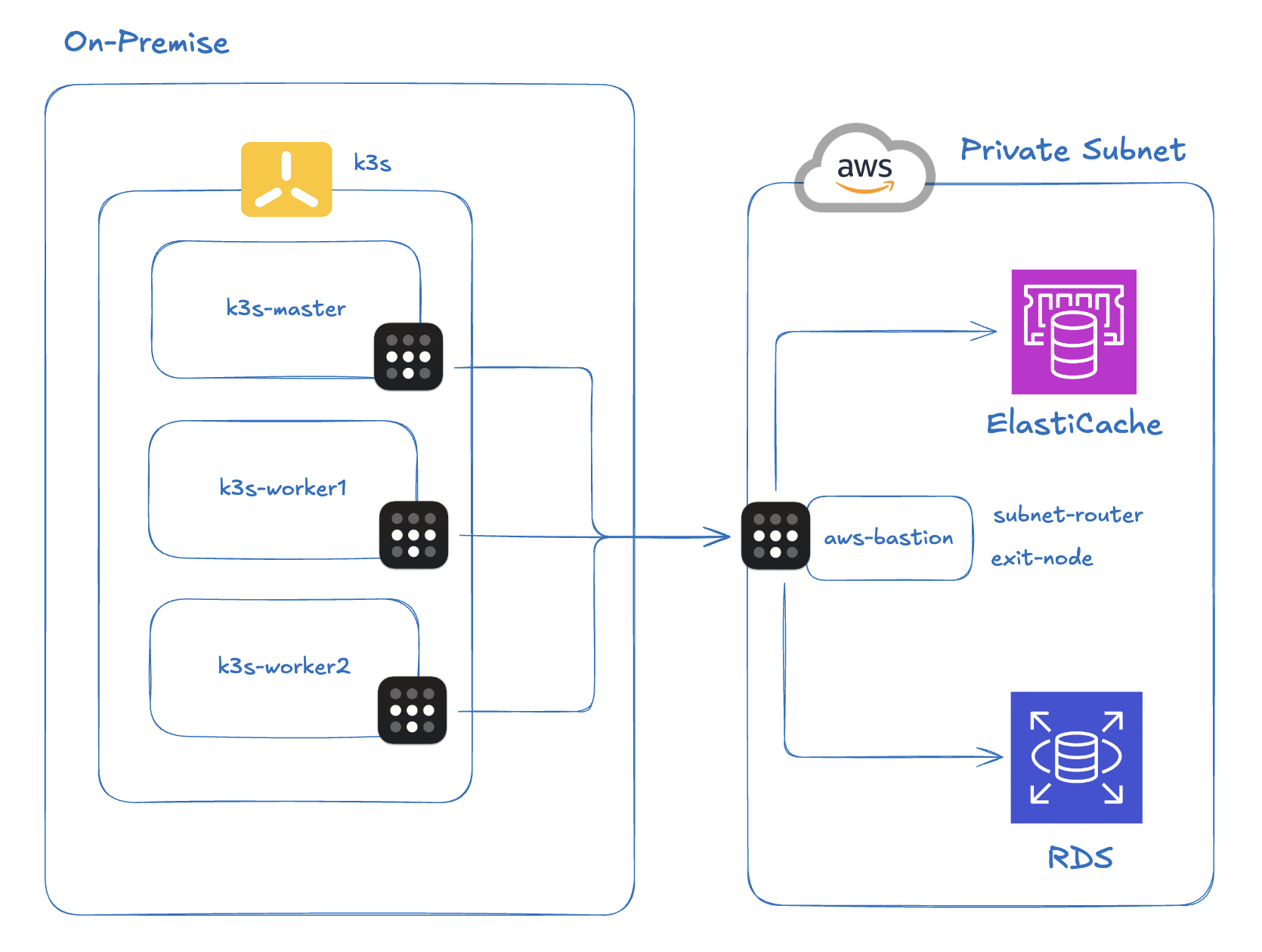
1. インフラ構成
まず、問題が発生した環境を紹介する。
K3sクラスター: オンプレミスにK3sで構築した軽量Kubernetes。Pod CIDRは
10.42.0.0/16。VPN: Tailscale(WireGuardベースのメッシュVPN)。AWS Private Subnetにアクセスできるよう、bastionインスタンスにTailscaleをインストールし、Subnet RouterでVPC CIDRをadvertiseする構成。オンプレミスの全ノードにもTailscaleを設定してある。
AWS ElastiCache: Private SubnetにあるRedis 7.1インスタンス。EC2 bastionを経由してのみアクセス可能で、オンプレミスからは必ずTailscaleトンネルを経由する必要がある。
アプリケーション: Spring Boot(Kotlin)ベースのNotificationサービス。ArgoCDでデプロイし、ElastiCacheにLettuceクライアントで接続する。AWS ECSからオンプレミスへの移行中にこの問題が発生した。
この構成のポイントは、オンプレミスのPod → Tailscaleトンネル → AWS Private SubnetのRedisという経路だ。Podから出たパケットはFlannelのVXLANを経由してノードに出た後、TailscaleのWireGuardトンネルを通ってAWSまで到達する。つまり、カプセル化が二重に発生する構造だ。
2. 問題発生:Redisヘルスチェックの失敗
ArgoCDでNotificationサービスをデプロイしたところ、PodがReady状態に遷移しなかった。Spring Bootアプリ自体は13秒で正常に起動し、Redis TCPの接続も成功した。しかしSpring Boot ActuatorのRedisヘルスチェックが繰り返し失敗し、PodがNot Readyのままだった。
最初はネットワーク自体に問題があると思った。ElastiCacheのDNS名前解決ができていないと思い込み、ノードレベルからPodレベルへと順に接続を確認した。しかしすべて正常で、6379ポートへのpingも成功した。
ログを詳しく見ると、興味深いパターンが見えてきた。
正常:HELLO / CLIENTコマンド
01:22:20.983 [lettuce-nioEventLoop-6-1] DEBUG CommandHandler
- write(ctx, AsyncCommand [type=HELLO, ...])
01:22:21.039 [lettuce-nioEventLoop-6-1] DEBUG CommandHandler
- Received: 150 bytes, 1 commands in the stack
01:22:21.051 [lettuce-nioEventLoop-6-1] DEBUG CommandHandler
- Completing command [type=HELLO, output={server=redis, version=7.1.0, proto=3, ...}]
01:22:21.053 [lettuce-nioEventLoop-6-1] DEBUG CommandHandler
- write(ctx, [AsyncCommand [type=CLIENT, ...], AsyncCommand [type=CLIENT, ...]])
01:22:21.062 [lettuce-nioEventLoop-6-1] DEBUG CommandHandler
- Received: 10 bytes, 2 commands in the stack
01:22:21.063 [lettuce-nioEventLoop-6-1] DEBUG CommandHandler
- Completing command [type=CLIENT, output=OK]
よく見ると、Connection Timeoutではなく、ヘルスチェックで失敗している状況だった。HELLO(150B)、CLIENT(10B)はCompleting commandログが正常に出力されている。
異常:INFOコマンド — レスポンスなし
01:22:21.085 [http-nio-8081-exec-3] DEBUG RedisChannelHandler
- dispatching command AsyncCommand [type=INFO, ...]
01:22:21.089 [lettuce-nioEventLoop-6-1] DEBUG CommandEncoder
- writing command AsyncCommand [type=INFO, ...]
# ⚠️ この後Receivedログなし — レスポンスが返ってこない
01:22:30.582 [http-nio-8081-exec-4] DEBUG RedisChannelHandler
- dispatching command AsyncCommand [type=INFO, ...]
# ⚠️ Receivedログなし — 10秒間隔でリトライを繰り返す
01:22:40.623 ... [type=INFO, ...] # ⚠️ レスポンスなし
01:22:50.664 ... [type=INFO, ...] # ⚠️ レスポンスなし
01:23:00.705 ... [type=INFO, ...] # ⚠️ レスポンスなし
INFOコマンドを送るとwriting commandログまでは出力されるが、Receivedログがまったく出ない。レスポンス自体が返ってきていないのだ。10秒間隔でリトライを続けても結果は変わらない。
パターン整理:パケットサイズによるトンネル通過の違い
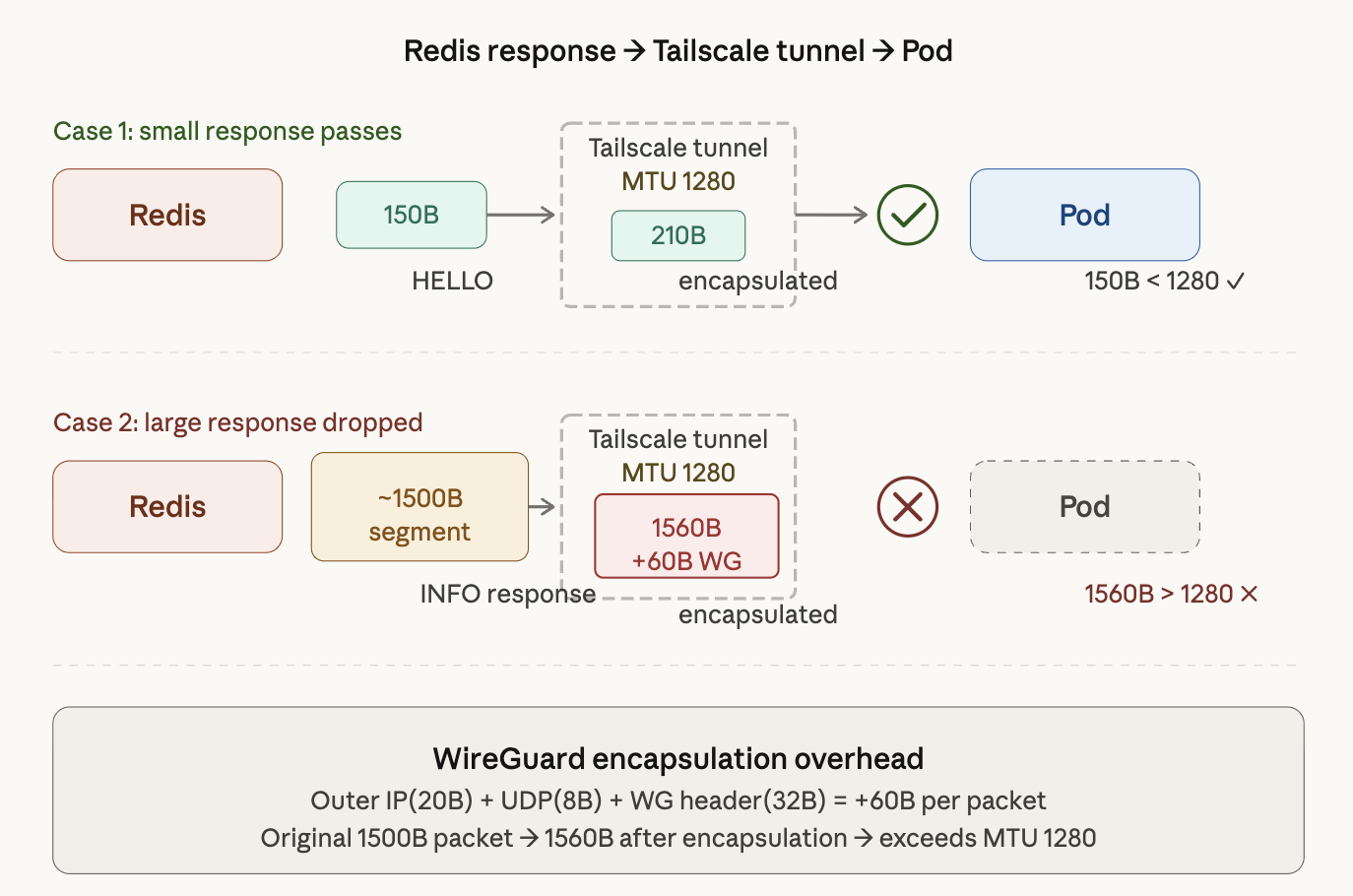
上の図は、RedisレスポンスがTailscaleトンネルを経由してPodに到達する2つのシナリオを示している。
Case 1: 小さなレスポンスは通過する。 HELLOコマンドの150Bレスポンスは、カプセル化後でも約210Bだ。TailscaleトンネルのMTU 1280を余裕で下回るため、パケットは正常にPodまで到達する(150B < 1280)。
Case 2: 大きなレスポンスはドロップされる。 INFOコマンドのレスポンスは約1500Bのセグメントとして送られてくる。ここにWireGuardカプセル化のオーバーヘッド60Bが加わると1560Bとなり、Tailscaleトンネルのメ MTU 1280を超える。結果としてパケットはドロップされ、Pod側ではレスポンスを永遠に待ち続けることになる。
小さなパケットは通過し、大きなパケットだけが消える。 これが決定的な手がかりだった。パケットサイズによって成功と失敗が分かれる時点で、MTU問題を疑うことができた。
3. 原因の特定:MTU仮説
パケットサイズによって成功と失敗が分かれる現象は、MTU問題の典型的な症状だ。他の可能性も検討したが、いずれも可能性が低かった。
- Redis ACL/権限の問題? → 権限がなければエラーレスポンスが返るはずだ。レスポンス自体がないのはネットワークレベルの問題を示す。
- Redisの過負荷? → INFOは軽量なコマンドだ。サーバーの問題であれば、すべてのコマンドに影響が出るはずだ。
- Tailscaleの設定問題? → 同じセキュリティグループのRDSには正常に接続できていた。
MTU仮説を確認するため、ワーカーノードでDF(Don’t Fragment)ビットを設定したpingテストを実施した。
uoslife@k3s-worker2:~$ ping -M do -s 1400 10.128.168.231
PING 10.128.168.231 (10.128.168.231) 1400(1428) bytes of data.
ping: local error: message too long, mtu=1280
ping: local error: message too long, mtu=1280
ping: local error: message too long, mtu=1280
-M doはDFビットを設定するオプションで、-s 1400はICMPペイロードサイズを1400バイトに指定するオプションだ。結果はすぐにmessage too long, mtu=1280で失敗した。1400 + 28(IP 20B + ICMP 8B)= 1428バイトがTailscaleインターフェースのMTU 1280を超えるためだ。
uoslife@k3s-worker2:~$ ping -M do -s 1200 10.128.168.231
PING 10.128.168.231 (10.128.168.231) 1200(1228) bytes of data.
# パケットは送出される(1228 < 1280)
1200バイトに減らすとパケットは送出される。Tailscaleインターフェース(tailscale0)のMTUが1280に設定されていることが確認できた。では、MTUがなぜ問題になるのか、その仕組みを見ていこう。
4. MTUの概念整理
このセクションでは、トラブルシューティングの流れをいったん止めて、MTUに関連する重要な概念を整理する。
4.1 MTUとMSS
MTU(Maximum Transmission Unit)は、ネットワークインターフェースが一度に送信できる最大パケットサイズだ。正確には、L2フレームのペイロード、つまりL3(IP)パケットの最大サイズを意味する。イーサネットの標準MTUは1500バイトだ。
この意味を理解するために、OSIレイヤー別のデータ単位を先に確認しておこう。下の図は널널한 개발자の講義から引用した内容だ。
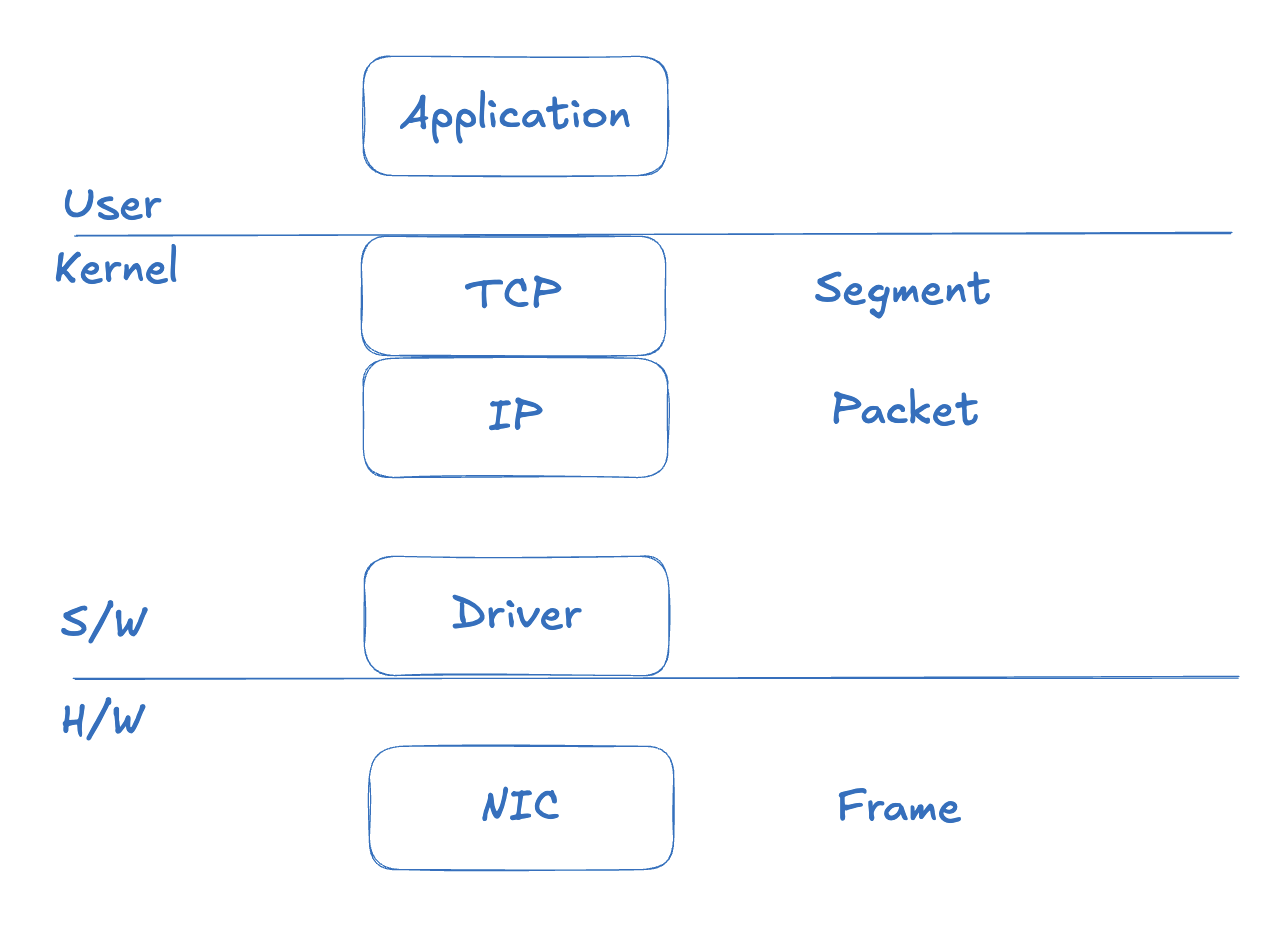
TCPレイヤーではセグメント(Segment)、IPレイヤーではパケット(Packet)、データリンクレイヤー(NIC)では**フレーム(Frame)**という単位を使う。上位レイヤーから下位レイヤーに移るほど、ヘッダーが追加されていく。
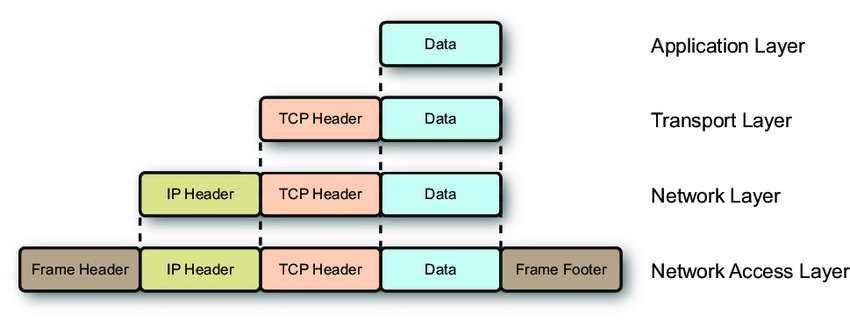
MTUが1500バイトで、IPヘッダー20B + TCPヘッダー20Bを引くと、ペイロードは最大1460バイトになる。なお、Ethernet Frame Header(14B)とFCS(4B)はMTUの計算に含まれない。MTUはL3以上のサイズのみをカウントする。
ここで重要な概念が**MSS(Maximum Segment Size)**だ。MSSは1つのTCPセグメントに載せられる最大アプリケーションデータサイズで、MTUからIPヘッダーとTCPヘッダーを引いた値だ。
MSS = MTU - IP Header - TCP Header
MSS = 1500 - 20 - 20 = 1460 バイト
TCPは接続確立(3ウェイハンドシェイク)時に自分が出ていくインターフェースのMTUを参照してMSSをネゴシエーションする。アプリケーションが10KBのデータを送るよう要求すると、TCPがMSSサイズに分割してセグメントを作る。
4.2 フラグメンテーションとDFビット
パケットが経路の途中でMTUを超えた場合、2つのことが起こりうる。
シナリオ1:フラグメンテーション(断片化)
IPヘッダーのDF(Don’t Fragment)ビットがオフになっていると、ルーターがパケットをMTUに合わせて分割して送信する。受信側で再組み立てするが、パフォーマンス低下があり、断片の1つでも欠損すると全体を再送しなければならない。
シナリオ2:パケットドロップ + ICMPエラー
DFビットがオンになっている場合(最近のほとんどのTCPパケット)、ルーターがパケットをドロップしてICMP「Fragmentation Needed」メッセージを返す。送信側がこのメッセージを受け取り、パケットサイズを小さくして再送する。これが**Path MTU Discovery(PMTUD)**のメカニズムだ。
ただし、VPNやファイアウォール環境ではICMPがブロックされてPMTUDが機能しないケースが多い。このとき送信側は、パケットがなぜドロップされているかわからないままタイムアウトを迎えることになる。これをPMTUD Black Holeと呼ぶ。
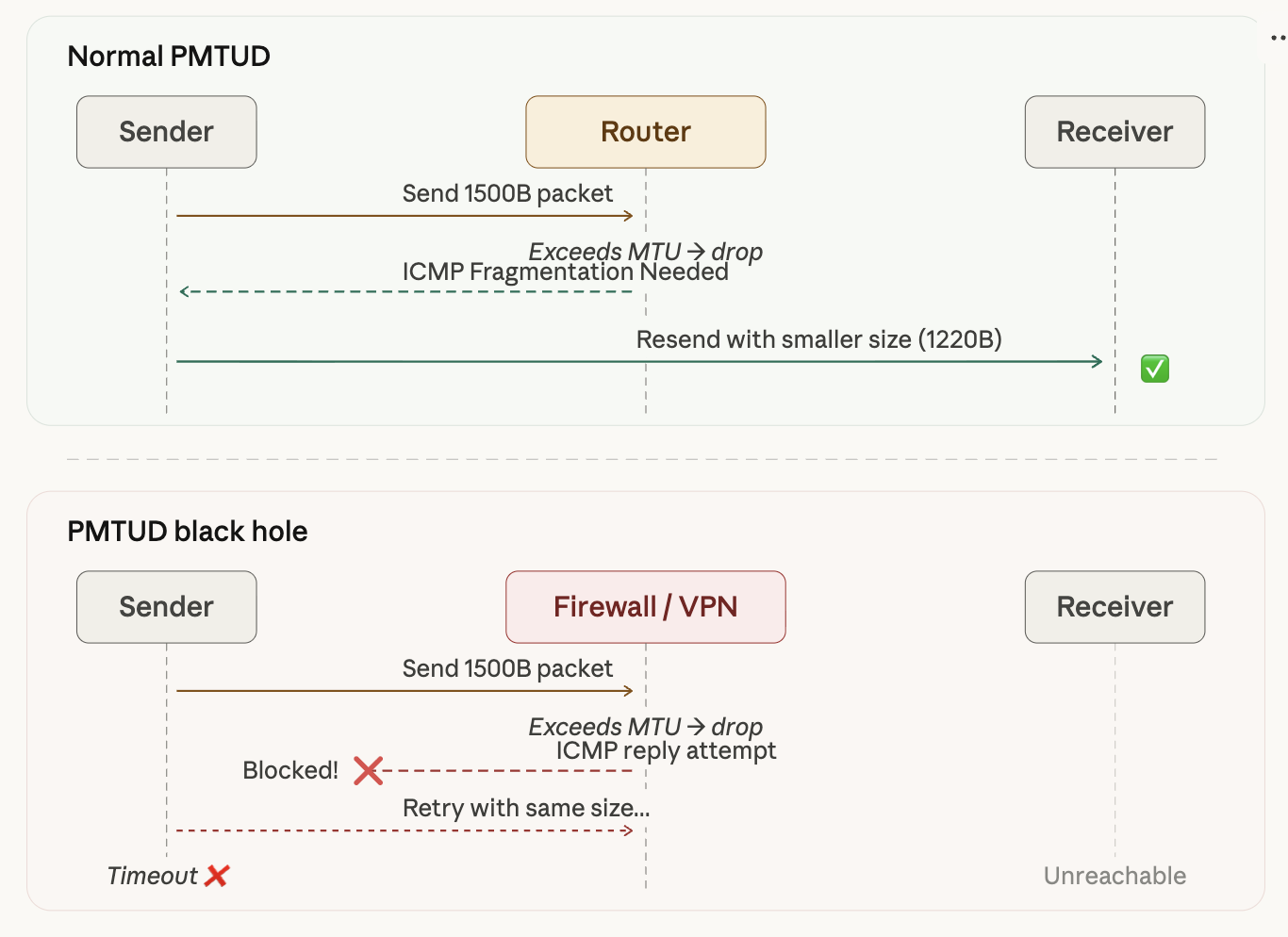
上の図のように、正常なPMTUDではルーターがICMPでMTU超過を通知し、送信側がパケットサイズを小さくして再送する。しかしVPN/ファイアウォール環境ではICMPがブロックされ、送信側はドロップの原因を知ることができず、同じサイズで再送を繰り返してタイムアウトに陥る。
4.3 WireGuard(Tailscale)の二重カプセル化問題
ここが核心だ。WireGuardはL3 VPNで、IPパケットをまるごとカプセル化する。この過程で約60バイトのオーバーヘッドが追加される。
WireGuardオーバーヘッド: Outer IP(20B) + UDP(8B) + WG Header(32B) = 60B
カプセル化のプロセスをステップごとに見ていこう。
ステップ1:アプリがパケットを作る
アプリケーションはトンネルの存在を知らない。通常通りデータを送信する。
[Inner IP 20B] [Inner TCP 20B] [Payload 1460B] = 1500B
ステップ2:WireGuard(Tailscale)がカプセル化する
元の1500Bパケットを「データ」として扱い、外側に新しいヘッダーを被せる。
[Outer IP 20B] [UDP 8B] [WG Header 32B] [元のパケット 1500B] = 1560B
ステップ3:物理NICの通過を試みる
物理NICのMTUは1500Bだが、カプセル化されたパケットは1560Bだ。MTU超過 → ドロップ。
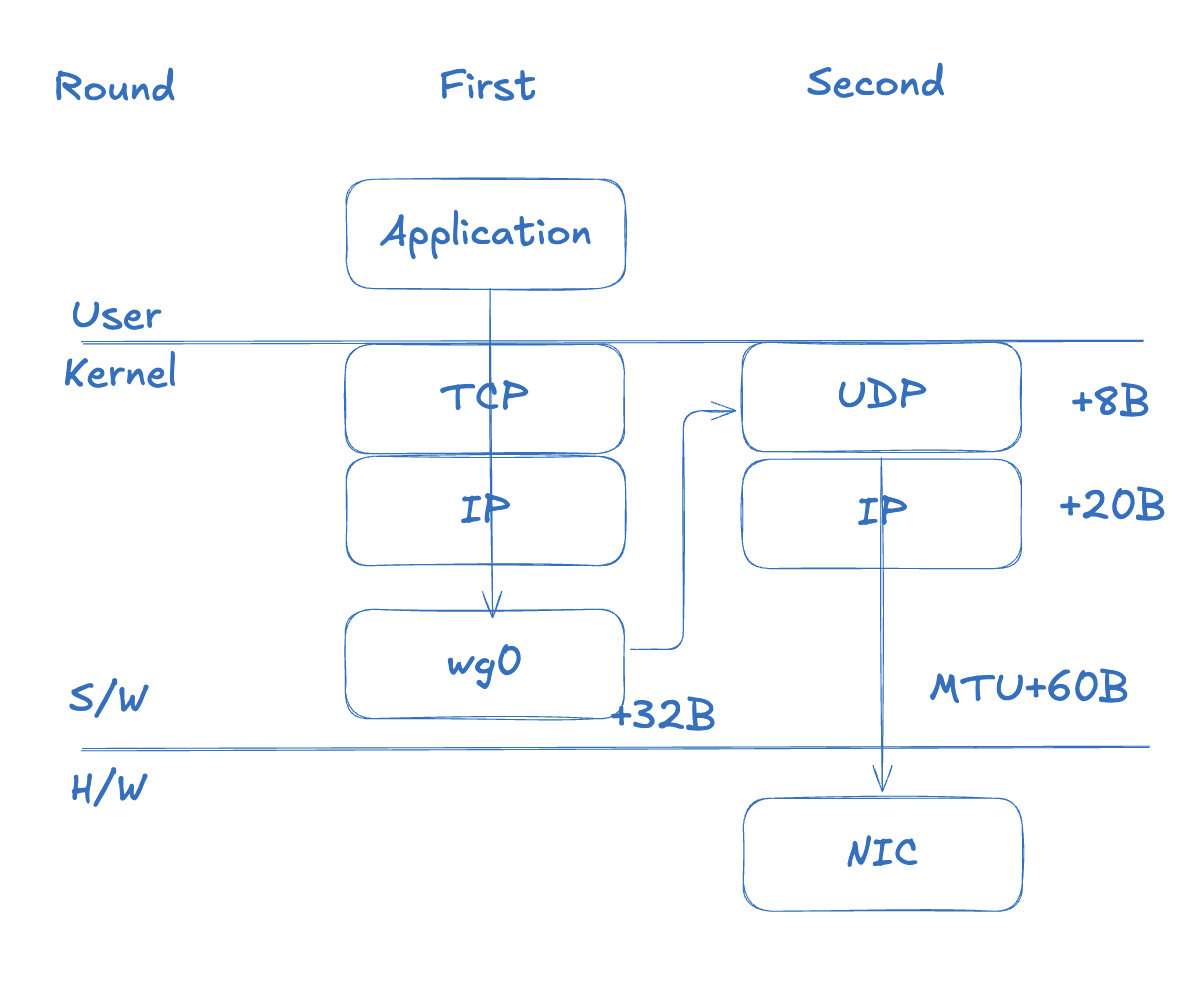
WireGuardベースのVPNでは、パケットが2つのレイヤーを経由して送信される。まずTCP/IPレイヤーを経た1500BパケットがカーネルのWireGuard仮想インターフェース(wg0、tailscale0)に到達する。wg0でパケットを暗号化し、WGヘッダー(32B)を追加して新しいUDPペイロードを作る。その後、UDPヘッダー(8B)、Outer IPヘッダー(20B)が順に付加され、最終的に1560Bになる。
TCPレイヤーでのデータ単位をセグメント(Segment)と呼ぶのに対して、UDPレイヤーではデータグラム(Datagram)と呼ぶ。
まとめると、WireGuardでカプセル化されたパケットは次のようにMTUを超過する。
通常のパケット:
[IP 20B] [TCP 20B] [Payload 1460B] = 1500B
→ 物理NIC MTU以内 ✅
WireGuardカプセル化後:
[Outer IP 20B] [UDP 8B] [WG 32B]
+ [Inner IP 20B] [TCP 20B] [Payload 1460B]
= 1560B
→ MTU超過 ❌
すでにぎっしり詰まった荷物を国際配送用の箱に入れ直さなければならないのに、外側の箱のサイズ制限も同じで入りきらない、という状況と同じだ。
TCPが自動で調整できない理由
TCPはMSSネゴシエーション時に、自分が出ていくインターフェースのMTUを参照する。トンネルインターフェース(tailscale0)のMTUが1500に設定されていると、TCPはMSS 1460でネゴシエーションする。WireGuardが60Bを追加することは、TCPが知る余地のない領域だ。これがIP-in-UDPカプセル化の落とし穴だ。
実際の環境で何が起きていたか
今回の環境のTailscaleはMTUを1280に設定していた。これはIPv6最小MTU互換のためにTailscaleが保守的に設定した値だ。ところが、Pod内部のTCPスタックがこの値を正しく反映できていなかったことが問題だった。
Redis PING(小さなパケット):
Inner: [IP+TCP+PING ≈ 50B] = 50B
カプセル化後: 50 + 60 = 110B → ✅ 通過
Redis INFOレスポンス(大きなパケット):
Inner: [IP+TCP+INFO ≈ 1500B] = 1500B
カプセル化後: 1500 + 60 = 1560B → ❌ ドロップ
HELLO(150B)、CLIENT(10B)のような小さなレスポンスは、カプセル化してもMTU以内なので問題ない。しかしINFOレスポンス(約5KB)はMTUを超えるセグメントが含まれるためドロップされる。**「接続はできているのに、ヘルスチェックだけが失敗する」**というのは、まさにこういう仕組みだった。
5. 解決:MSS Clampingの適用
原因を特定できたので、解決策はTCP MSSをトンネルのMTUに合わせて強制的に下げることだ。これをMSS Clampingと言う。
適用したiptablesルール
sudo iptables -t mangle -A FORWARD -o tailscale0 \
-p tcp --tcp-flags SYN,RST SYN \
-j TCPMSS --clamp-mss-to-pmtu
各オプションの意味は次の通りだ。
| オプション | 説明 |
|---|---|
-t mangle | パケット変更(mangle)テーブル |
-A FORWARD | ノードを経由(forward)するパケットに適用(Pod → 外部トラフィック) |
-o tailscale0 | tailscale0インターフェースに出ていくパケットを対象 |
-p tcp --tcp-flags SYN,RST SYN | TCP SYNパケットのみを対象(ハンドシェイクのタイミング) |
-j TCPMSS --clamp-mss-to-pmtu | MSS値をPath MTUに合わせて自動調整 |
このルールはTCP 3ウェイハンドシェイクのSYNパケットで、MSS値をtailscale0インターフェースのMTU(1280)に合わせて自動調整する。こうすることで、ElastiCacheがレスポンスを返す際により小さなセグメントに分割して送るようになる。
適用直後の結果
01:38:20.012 [http-nio-8081-exec-2] DEBUG RedisChannelHandler
- dispatching command AsyncCommand [type=INFO, ...]
01:38:20.014 [lettuce-nioEventLoop-6-1] DEBUG CommandEncoder
- writing command AsyncCommand [type=INFO, ...]
01:38:20.022 [lettuce-nioEventLoop-6-1] DEBUG CommandHandler
- Received: 1024 bytes, 1 commands in the stack
01:38:20.022 [lettuce-nioEventLoop-6-1] DEBUG RedisStateMachine
- Decode done, empty stack: false
01:38:20.022 [lettuce-nioEventLoop-6-1] DEBUG CommandHandler
- Received: 4175 bytes, 1 commands in the stack
01:38:20.023 [lettuce-nioEventLoop-6-1] DEBUG RedisStateMachine
- Decode done, empty stack: true
01:38:20.023 [lettuce-nioEventLoop-6-1] DEBUG CommandHandler
- Completing command [type=INFO, output=# Server redis_version:7.1.0 ...]
01:38:20.024 [http-nio-8081-exec-2] DEBUG RedisConnectionUtils
- Closing Redis Connection
INFOレスポンスが複数のTCPセグメントに分割されて届いているのがわかる。1回目のReceived: 1024 bytesでDecode done, empty stack: false(まだ続きがある)が出力され、2回目のReceived: 4175 bytesでDecode done, empty stack: true(デコード完了)で締め括られる。合計約5,199バイトが正常に受信された。
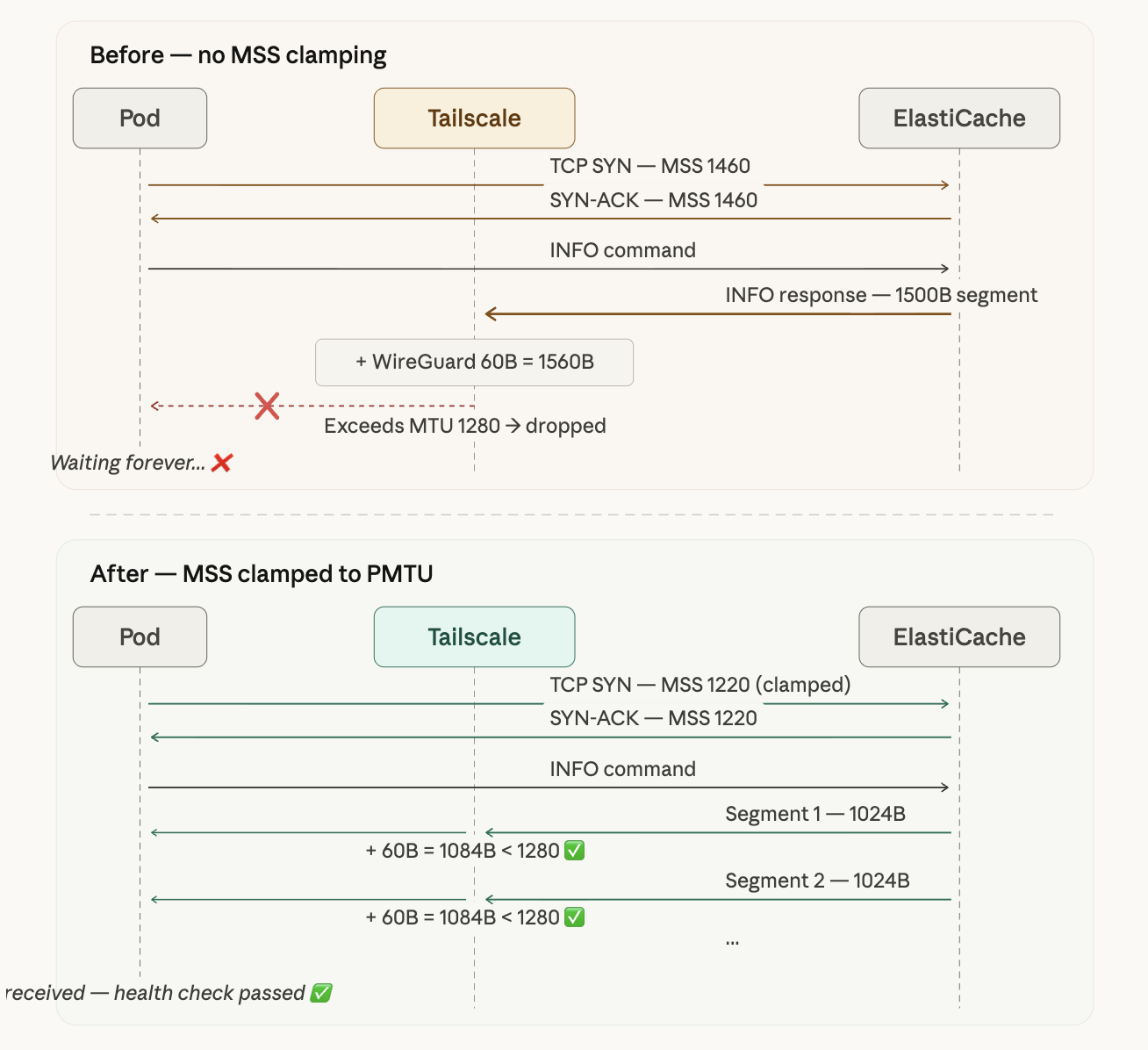
上の図はMSS Clamping適用前後の違いを示している。Before(適用前)ではMSS 1460でネゴシエーションされ、INFOレスポンスが1500Bの単一セグメントとして送られてくるため、カプセル化後に1560Bとなってドロップされる。After(適用後)ではMSSが1220にクランプされ、INFOレスポンスが1024B単位の小さなセグメントに分割され、カプセル化後もMTU 1280以内で正常に通過する。
適用前後の比較
| 項目 | Before | After |
|---|---|---|
| HELLO(150B) | ✅ 正常受信 | ✅ 正常受信 |
| CLIENT(10B) | ✅ 正常受信 | ✅ 正常受信 |
| INFO(約5KB) | ❌ レスポンスドロップ | ✅ 1024B + 4175B に分割受信 |
| ヘルスチェック | ❌ 失敗(Pod Not Ready) | ✅ 成功(Pod Ready) |
6. 第二の問題:別のワーカーノード
最初のPodが正常化してひと安心していたところ、2つ目のPodレプリカがまだReady状態にならないという問題が残っていた。
原因は単純だった。MSS Clampingをk3s-worker2の1台にしか適用していなかったのに、2つ目のPodが別のワーカーノードにスケジュールされていたのだ。iptablesルールはノードごとに独立しているため、自動的には伝播しない。
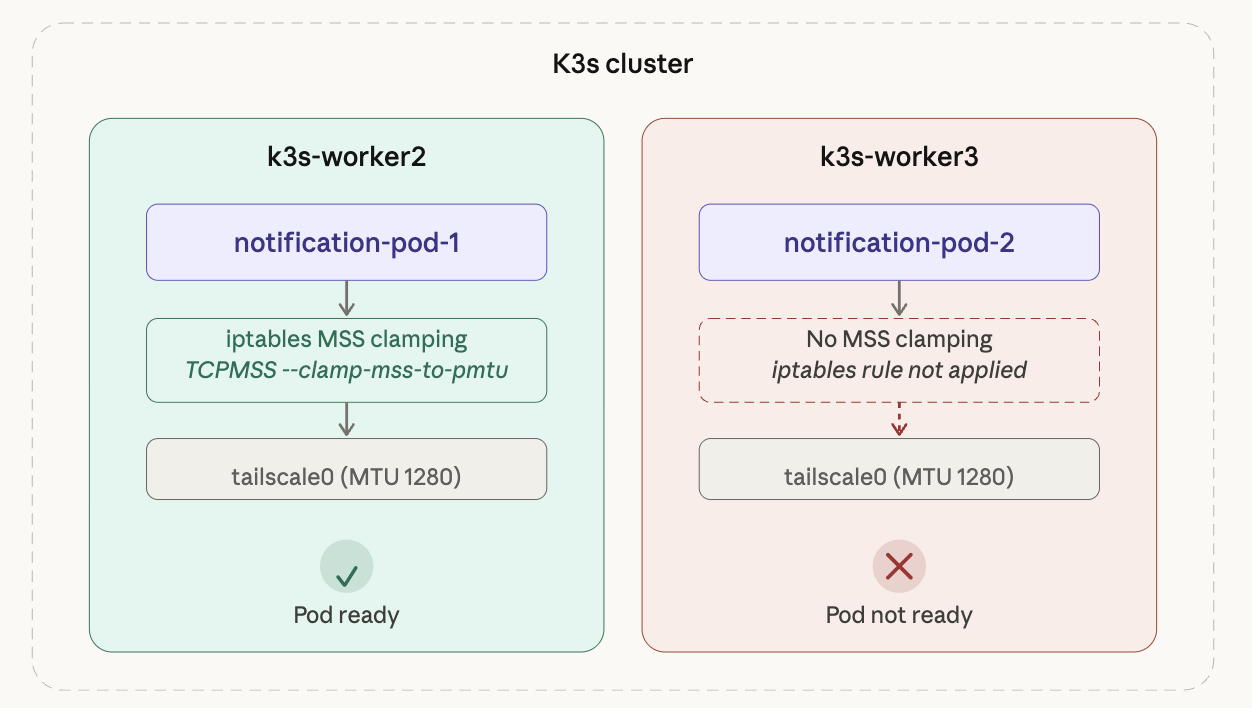
k3s-worker2にはiptablesルールが適用されてPodがReady状態だが、k3s-worker3にはルールがなく、同じ問題が再現した。
# 各Podがどのノードにスケジュールされているかを確認
kubectl get pods -n <namespace> -o wide | grep notification
解決は簡単だ。すべてのワーカーノードに同じiptablesルールを適用すればよい。
# すべてのワーカーノードで実行
sudo iptables -t mangle -A FORWARD -o tailscale0 \
-p tcp --tcp-flags SYN,RST SYN \
-j TCPMSS --clamp-mss-to-pmtu
適用後、2つ目のPodも正常にReady状態に遷移した。
Kubernetesにおけるネットワーク設定はノードレベルだ。Podはどのノードにスケジュールされるかわからないため、ネットワーク関連の設定は必ずすべてのノードに一貫して適用しなければならない。
7. 永続化
問題:再起動で消えるiptablesルール
iptablesコマンドで適用したルールはメモリ上にしか存在しない。ノードが再起動するとルールが消え、同じ問題が再発する。実際にワーカーノードにSSHで接続した際に*** System restart required ***メッセージが表示されていたため、永続化は必須だった。
方法1:iptables-persistent
最も簡単な方法はiptables-persistentをインストールして、現在のルールを永続化することだ。
sudo apt install iptables-persistent
sudo netfilter-persistent save
方法2:Flannel MTUの根本的な修正
MSS Clampingは応急処置に近い。根本的にはFlannelのMTUをTailscaleトンネルのMTUに合わせて設定するのが正しい方法だ。
サーバーノード(master)の/etc/rancher/k3s/config.yaml:
flannel-conf: /etc/rancher/k3s/flannel.json
/etc/rancher/k3s/flannel.json:
{
"Network": "10.42.0.0/16",
"EnableIPv4": true,
"EnableIPv6": false,
"Backend": {
"Type": "vxlan",
"VNI": 1,
"Port": 8472,
"MTU": 1220
}
}
MTU 1220の計算式は次の通りだ。
Tailscaleトンネル MTU: 1280
- VXLANオーバーヘッド: 50
- 余裕分: 10
────────────────────────────
Flannel MTU: 1220
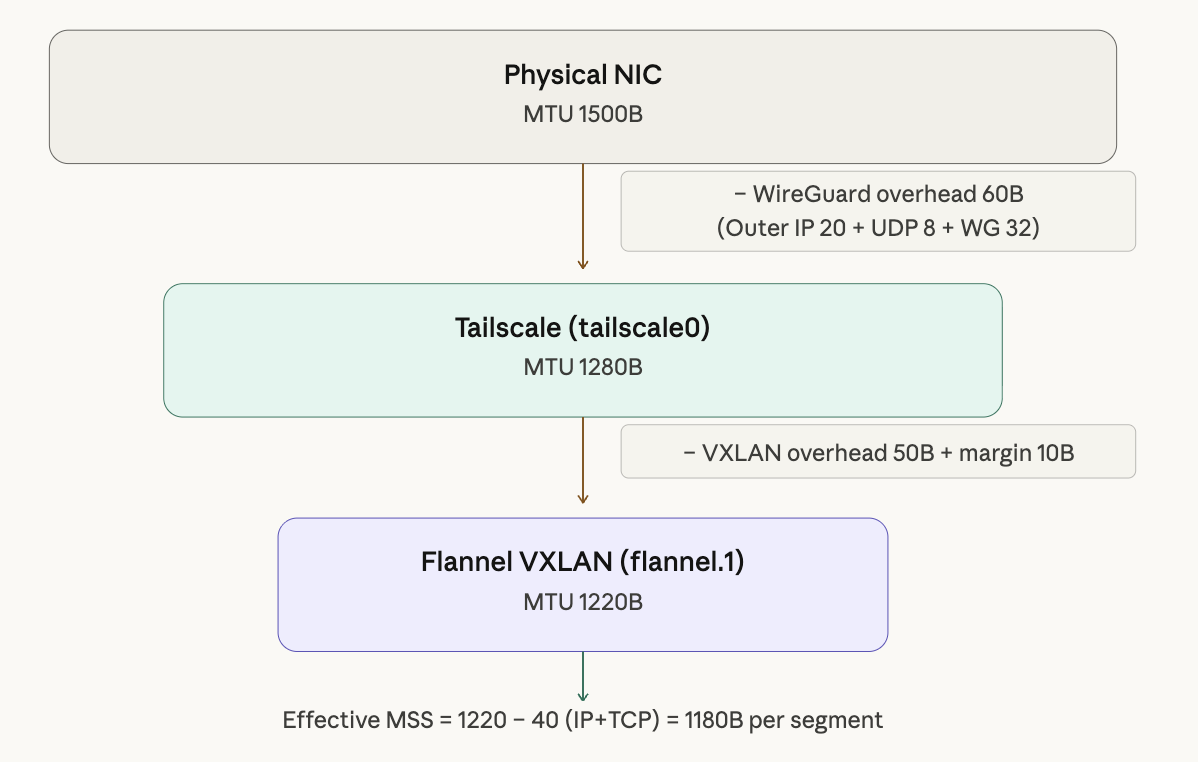
物理NIC(1500B)からWireGuardオーバーヘッド(60B)を引くとTailscale MTU 1280になり、さらにVXLANオーバーヘッド(50B)と余裕分(10B)を引くとFlannel MTU 1220になる。この値に設定することで、Podから出るパケットがすべてのカプセル化レイヤーを通過できるようになる。
適用手順
# 1. 現在のflannel設定を確認
cat /var/lib/rancher/k3s/agent/etc/flannel/net-conf.json
# 2. configファイル作成後にk3sを再起動(master)
sudo systemctl restart k3s
# 3. ワーカーノードを再起動
sudo systemctl restart k3s-agent
# 4. flannel MTUを確認
ip link show flannel.1
# 5. 既存Podのrollout restart(新しいMTUは新規Podにのみ適用される)
kubectl rollout restart deployment/<deployment-name> -n <namespace>
注意点がある。Flannel MTUの変更は実行中の既存Podのvethにはすぐに反映されない。変更後は既存のPodをrollout restartして、新しいMTUが適用されるようにする必要がある。全ワークロードに影響があるため、メンテナンス時間に実施することを推奨する。
8. 振り返り
学んだこと
今回のトラブルシューティングで得た教訓をまとめると次の通りだ。
- 「小さなパケットは通るのに大きなパケットは通らない」場合はMTUを疑え。 接続は成功するのにデータ転送だけが失敗するパターンは、MTU問題の典型的な症状だ。
- VPNトンネル環境では二重カプセル化を常に考慮する必要がある。 WireGuard 60B、VXLAN 50Bなど、各カプセル化レイヤーのオーバーヘッドを計算に含めなければならない。
- Kubernetesのネットワーク設定はノードレベルだ。 iptablesルールは自動伝播しないため、すべてのノードに一貫して適用する必要がある。
- 応急処置(MSS Clamping)と根本解決(MTU設定変更)を区別しよう。 障害時には迅速な回避が先決だが、その後必ず永続的な対応を行う必要がある。
デバッグコマンド集
# MTUの確認:DFビットを設定してping
ping -M do -s 1400 <target-ip>
# インターフェースごとのMTU確認
ip link show tailscale0
ip link show flannel.1
# MSS Clamping適用の確認
sudo iptables -t mangle -L FORWARD -v
WireGuardプロトコル補足
参考として、WireGuardの主な特徴をまとめると次の通りだ。
| 項目 | WireGuard | OpenVPN |
|---|---|---|
| トランスポート層 | UDP(常時) | TCPまたはUDP |
| 動作レベル | カーネルモジュール | ユーザースペース |
| コードサイズ | 約4,000行 | 数十万行 |
| 暗号化のネゴシエーション | なし(固定) | TLSベースのネゴシエーション |
WireGuardが常にUDPを使う理由がある。トンネルの内外で両方ともTCPを使うと、再送が重複して性能が急激に低下するTCP meltdown現象が発生する。外側のUDPは転送のみを担当し、内側のTCPが再送を担当する構造でこの問題を回避している。
Tailscaleは、このWireGuardの上にコントロールプレーン(鍵の配布、NATトラバーサル、DERPリレーなど)を載せたものだ。トンネリング自体の動作は純粋なWireGuardと同じであるため、WireGuardのMTU関連の特性がTailscaleにもそのまま当てはまる。