前の記事ではJavaとSpringのマルチスレッドアーキテクチャを取り上げた。リクエスト一つにスレッド一つを割り当て、LockとSynchronizationメカニズムで共有リソースを管理する、伝統的なマルチスレッドモデルだった。ところが同じサーバーサイドの領域で、これとまったく対照的な哲学を持つ陣営がある。それがJavaScriptとNode.jsだ。
JavaScriptはシングルスレッドベースのノンブロッキングパラダイムを持つ非同期並行処理言語だ。Lockもなく、セマフォもなく、デッドロックもない。それなのに、どうやってシングルスレッドで数万の同時接続を処理できるのか。そしてNode.jsは本当にシングルスレッドなのか、それともマルチスレッドなのか。この議論がなぜ終わらないのか。
この記事では三つのテーマを一つの流れで扱う。まずJavaScriptのイベントループがシングルスレッド環境でどのように非同期処理を実装するかを分析し、Node.jsが「シングルスレッドかマルチスレッドか」という長年の議論に対してlibuvとともに答えを探す。最後にコールバックからasync/awaitまで、非同期プログラミングパラダイムの進化を整理する。
1. JavaScriptのイベントループ
JavaScriptがシングルスレッドかマルチスレッドかを知るためには、まずイベントループという概念を理解する必要がある。
V8エンジンの構造
JavaScriptを実行するV8エンジンは、GoogleがC++で作成したJavaScriptエンジンだ。Google Chromeに搭載されてJavaScriptを動作させる役割を担っており、オープンソースであるためNode.jsでも活用されている。
V8エンジンの動作原理は次の通りだ。
- JavaScriptのソースコードをパーサー(Parser)に渡す。
- パーサーはソースコードをAST(Abstract Syntax Tree、抽象構文木)に変換する。
- ASTをIgnitionインタープリターに渡すと、JavaScriptをバイトコードに変換する。
- バイトコードを実行しながら、頻繁に実行されるコードはTurboFanコンパイラーに送って最適化されたマシンコードにコンパイルする。

以上の過程がJavaScriptを実行するV8エンジンの原理だ。
シングルコールスタックと非同期処理
“Single thread == single call stack == one thing at a time” - Philip Roberts
V8エンジンは一つのCall Stackを持っている。構造的に一度に一つしか処理できない、名実ともにシングルスレッド言語だ。それなのに、このシングルスレッド言語がどうやってマルチスレッドに匹敵するパフォーマンスを出せるのか。
その秘密はWeb APIs、イベントループ(Event Loop)、コールバックキュー(Callback Queue)の協力にある。
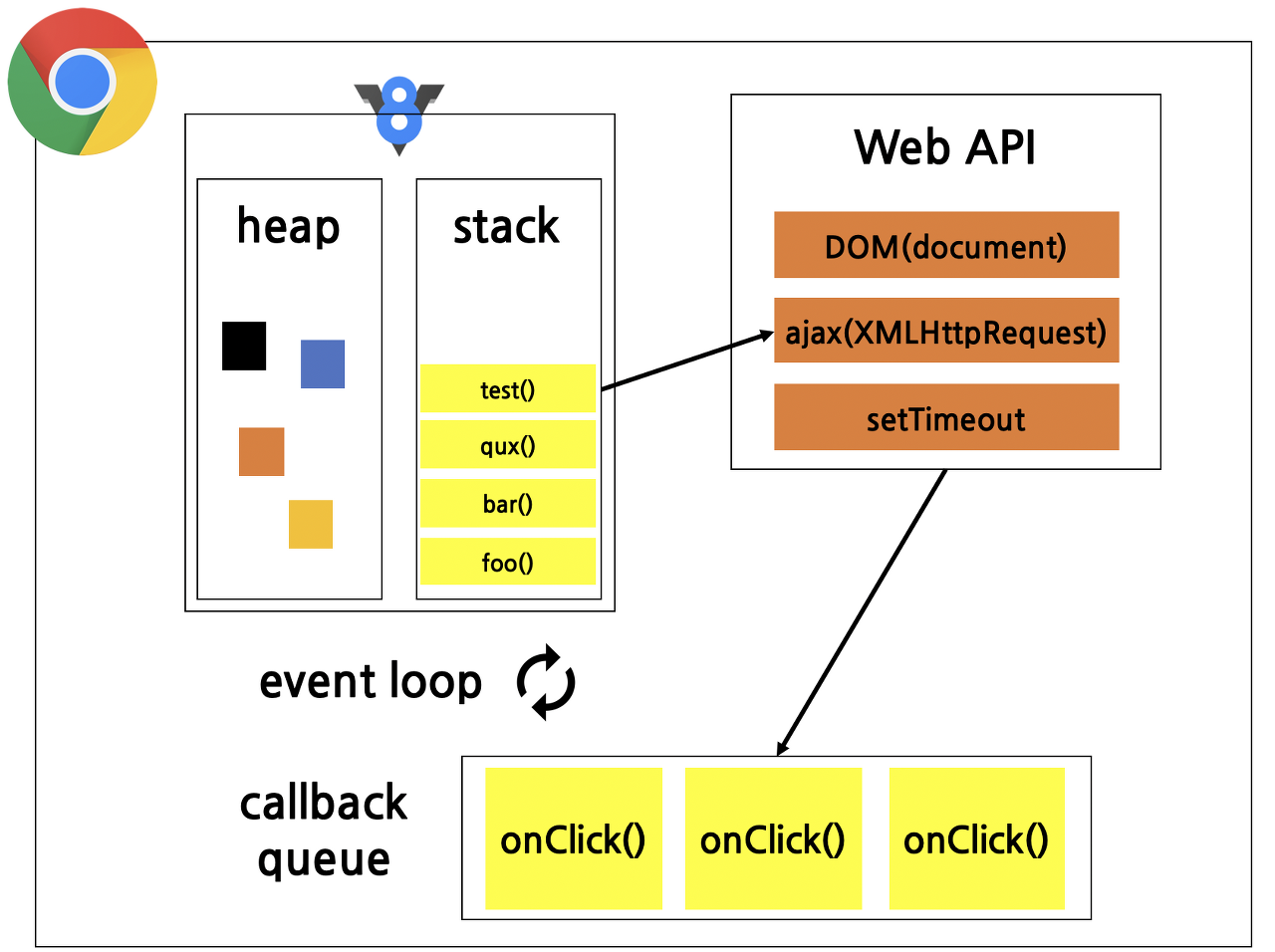
上の図はChromeブラウザに搭載されたJavaScriptランタイム環境だ。図を見るとV8というロゴとともに、一つのヒープと一つのコールスタックがあるのがわかる。つまりV8エンジンが実行するJavaScriptは、一般的に一つのコールスタックを使用する。
V8エンジンのCall Stackの隣で、Web APIs、Callback Queue、Event Loopが連携して動作する。非同期処理をサポートする操作(setTimeout、ネットワークリクエストなど)はWeb APIsで処理され、処理が終わるとCallback Queueに送られる。その後Event Loopがこれを検知して、Call Stackが空になったタイミングで適切に関数を押し込む。
つまりブラウザレベルでは、Web APIsとCallback Queueの助けを借りて非同期的に動作し、シングルスレッドでありながら非同期ベースで十分なパフォーマンスを発揮できる。ここで同期と非同期の処理について見ていこう。
同期関数の実行フロー
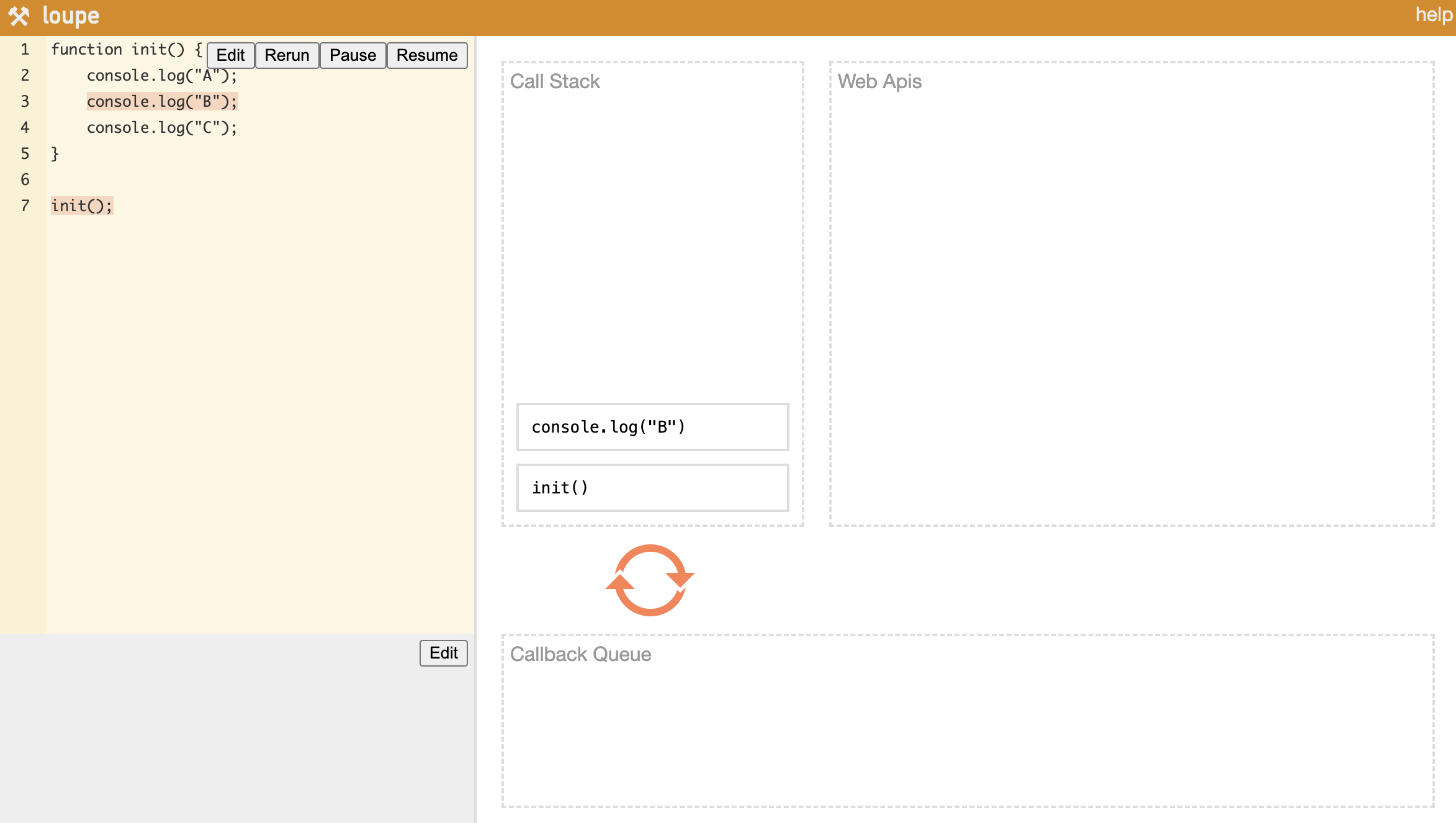
非同期関数がない一般的なケースを見てみよう。init()関数を呼び出すと、その中のconsole.logがCall Stackに積まれる。積まれたconsole.logはすぐに処理され、すべての処理が終わると最後にinit関数がCall Stackから取り除かれて実行が終了する。
非同期関数の実行フロー
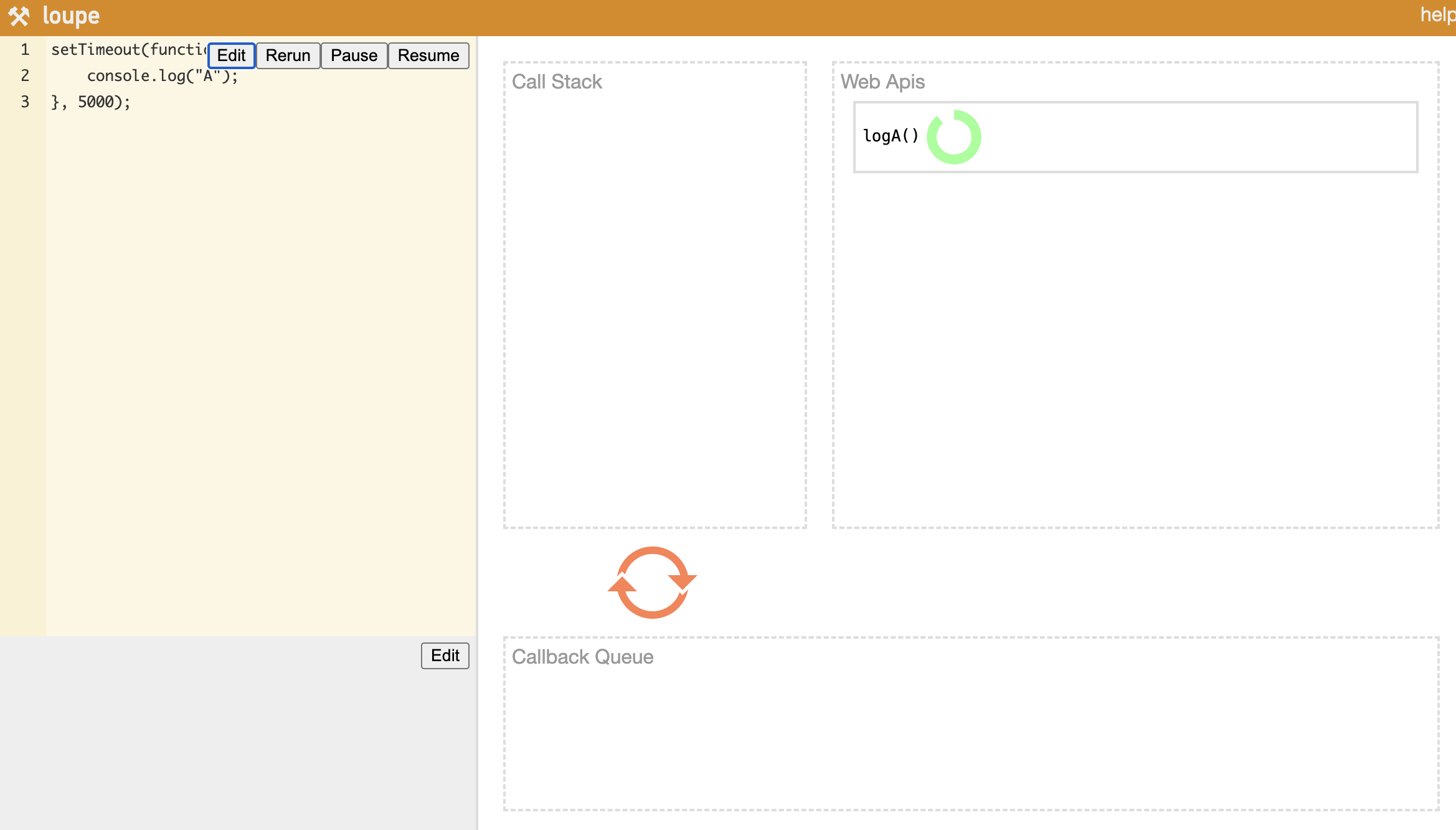
最も代表的な非同期関数はsetTimeoutだ。setTimeoutのような非同期関数はまずCall Stackに積まれ、その後Web APIsに移動する。Web APIs内でタイマー処理が終わるとコールバック関数をCallback Queueに入れ、Event Loopがそれを一つずつCall Stackに送り込む。
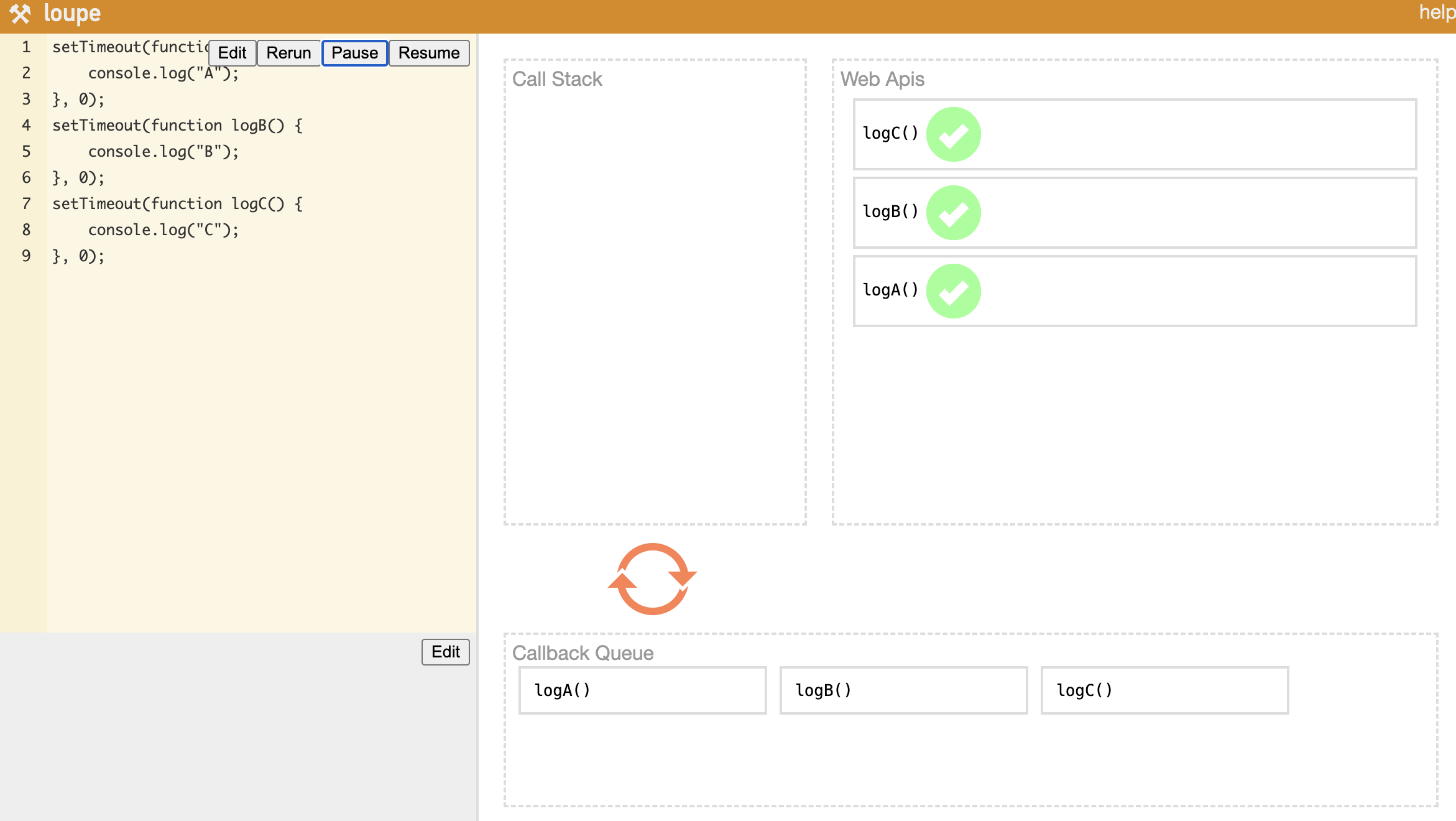
setTimeoutを複数使う場合、ソースコードを一行ずつ読みながら順番にCall Stackに入り、Web APIsに送られる。その後各コールバック関数の処理が完了するとCallback Queueに積まれ、Event Loopが一つずつCall Stackに送る。このメカニズムのおかげでCall Stack、Web APIs、Callback Queue、Event Loopが相互作用し、シングルスレッドベースのJavaScriptがマルチスレッドに引けを取らないパフォーマンスを発揮できる。
2. Node.jsのスレッディングモデル
イベントループのおかげでシングルスレッドのJavaScriptが非同期処理を行えることはわかった。ところがこのメカニズムがブラウザを離れてサーバーサイドに移ると話が変わる。Node.jsはこの構造をどのように取り込み、本当にシングルスレッドなのだろうか。
Node.jsとは何か
Node.js公式サイトの紹介によると次の通りだ。
Node.js はオープンソースのクロスプラットフォーム JavaScript ランタイム環境です。Node.js は Google Chrome の中核である V8 JavaScript エンジンをブラウザの外で実行します。
核心はブラウザの外で実行するという点だ。JavaScriptはもともとウェブサイトのために生まれた言語で、1995年にNetscape CommunicationsのBrendan Eichによって開発された。ウェブブラウザ上でHTML、CSSとともに動作するV8エンジンを、ブラウザの外でも独立して実行できるようにしたのがNode.jsだ。
JavaScriptはそれ単体では実行しにくい。ブラウザ内でWeb APIsとともに実行されるが、Node.jsはWeb APIsの代わりにlibuvを使って非同期ベースでパフォーマンスを引き出している。
シングルスレッドかマルチスレッドか
JavaScriptは異論なく、生まれながらのシングルスレッドだ。しかしNode.jsをシングルスレッドと見るかマルチスレッドと見るかについては、観点の違いがある。結論から言えば「どちらも正しい」 — どこに焦点を当てるかによる。
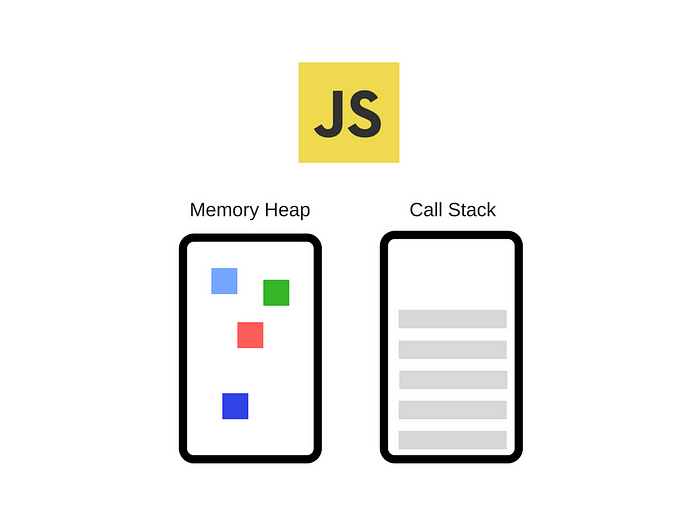
JavaScriptは一つのコールスタック(Call Stack)を持っており、Call Stack上のタスクを一つずつ処理するシングルスレッド方式で動作する。Memory Heapには変数などの情報が格納され、関数を実行するとCall Stackに一つずつ積まれる。
ブロッキング vs ノンブロッキング、同期 vs 非同期
JavaScriptのイベントループを理解するには、まずブロッキング/ノンブロッキングと同期/非同期の違いを知っておく必要がある。

- ブロッキング vs ノンブロッキング: 特定の関数を実行している間に他のことができるかどうかの違いだ。ブロッキングは関数が終わるまで待つ必要があり、ノンブロッキングは他の処理を並行して行える。制御権の有無が核心だ。
- 同期 vs 非同期: タスクの完了を誰が確認するかの違いだ。同期処理は呼び出し側が完了を直接確認し、非同期処理はコールバック(Callback)が完了を通知する。
JavaScriptがシングルスレッドでありながらマルチスレッドに引けを取らない理由は、ノンブロッキング非同期方式で動作するからだ。特定の処理をコールバックとして実行した後に別の処理を行い、非同期処理が完了してコールバック関数が戻ってきたときに結果を処理する方式だ。
非同期関数と非同期動作の違い
JavaScriptでasyncとawaitキーワードはそれぞれ次のような役割を持つ。
- async: 関数の前につけると、その関数は自動的に
Promiseを返す非同期関数になる。 - await: 非同期関数が完了するまで待ってから結果を返す。
重要なのは、非同期関数そのものが別途処理されるのではなく、非同期関数の中の非同期動作が別途処理されるという点だ。
async function example() {
console.log("1. 関数開始");
setTimeout(() => {
console.log("2. 非同期処理(setTimeout)完了");
}, 2000); // 2秒後に実行
console.log("3. 関数終了");
}
上のコードでsetTimeout()は非同期動作だ。実行すると1番と3番が先に出力され、2秒後に2番が出力される。setTimeoutで止まらずに残りのコードが先に実行されるのが核心だ。
awaitを使うと非同期動作の完了を待てる。
function delay(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
async function example() {
console.log("1. 関数開始");
await delay(2000); // 2秒待つ(非同期動作)
console.log("2. 2秒後に実行された");
}
example();
console.log("3. 関数実行後に別の処理を実行");
上のコードは、example()関数の実行中にawaitに出会うと、example()内部では2秒待つが、JavaScriptはノンブロッキング方式で動作するため"3. 関数実行後に別の処理を実行"が先に出力される。2秒後に"2. 2秒後に実行された"が出力される。
awaitなしで急いで非同期関数の結果を確認すると、まだ完了していないPromiseオブジェクトが返される。
async function example() {
return delay(2000); // awaitを使っていない
}
console.log(example()); // Promise { <pending> }
イベントループの動作構造
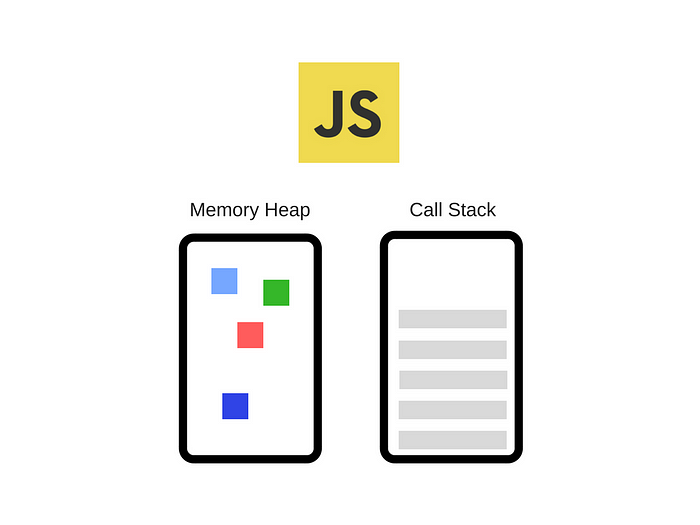
JavaScriptを実行するとCall Stack上の関数を一つずつシングルスレッドで処理する。ノンブロッキング非同期方式で動作するためには、非同期処理を代わりに担ってくれる存在が必要だ。
- Webブラウザ環境: Web APIsがマルチスレッド形式で非同期処理を行う。
- Node.js環境: libuvがマルチスレッドをサポートして非同期処理を行う。
まさにこの点においてJavaScriptをマルチスレッドと見なせる観点が生まれる。Web APIsとlibuvはそれぞれマルチスレッドで動作し、Javaのスレッドプールと同様にlibuvもスレッドプールを持っている。libuvのデフォルトのスレッドプールサイズは4つで、環境変数UV_THREADPOOL_SIZEで最大1024まで調整できる。

Callback Queue: Task QueueとMicrotask Queue
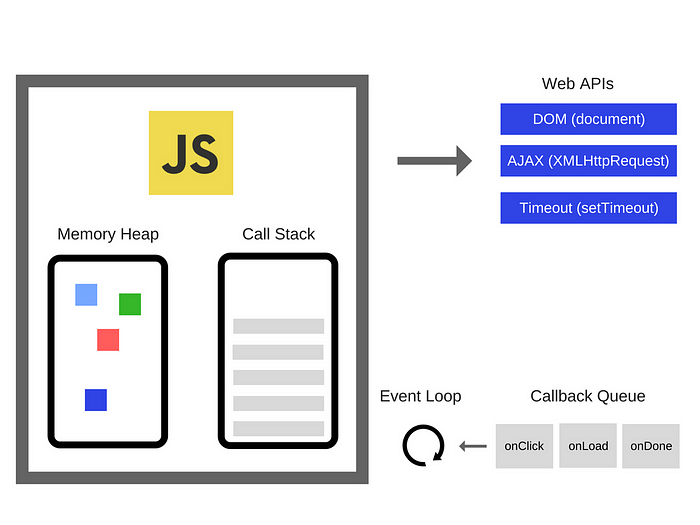
JavaScriptで実行されたすべての関数はまずCall Stackに入る。そのうち非同期関数はWeb APIs(またはlibuv)を呼び出し、完了したコールバック関数をコールバックキューに入れる。
コールバックキューは実は一つではなく二つある。
- Task Queue:
setTimeout、setIntervalなどが完了した後に実行されるコールバックが待機する場所 - Microtask Queue:
Promise.then()、MutationObserverなどのタスクが入るキュー
Microtask Queueの優先度が高い。 イベントループが一サイクル回るたびに最初に実行され、ほとんどが即座に実行される必要のある重要な非同期ロジックがここに入る。
Node.jsのprocess.nextTick()
Node.js環境ではもう一つ知っておくべきことがある。process.nextTick()で登録されたコールバックはMicrotask Queueよりも先に実行される。 正確には、イベントループの各フェーズが切り替わるたびにnextTickQueueが最初に空にされ、次にMicrotask Queue、最後にTask Queueの順で処理される。
setTimeout(() => console.log("1. Task Queue (setTimeout)"), 0);
Promise.resolve().then(() => console.log("2. Microtask Queue (Promise)"));
process.nextTick(() => console.log("3. nextTickQueue (process.nextTick)"));
console.log("4. Call Stack (同期コード)");
// 実行順序:
// 4. Call Stack (同期コード)
// 3. nextTickQueue (process.nextTick)
// 2. Microtask Queue (Promise)
// 1. Task Queue (setTimeout)
実行順序を見ると、同期コードが最初に実行され、次にprocess.nextTick()、Promise、setTimeoutの順だ。この優先度をまとめると次のようになる。
| 優先度 | キュー | 代表的なAPI |
|---|---|---|
| 1 (最優先) | nextTickQueue | process.nextTick() |
| 2 | Microtask Queue | Promise.then()、queueMicrotask() |
| 3 | Task Queue | setTimeout()、setInterval()、setImmediate() |
process.nextTick()を過度に使用すると、イベントループが次のフェーズに進めないI/O starvation問題が発生することがある。Node.js公式ドキュメントでも、多くの場合queueMicrotask()やsetImmediate()を推奨している。
Event Loopの6フェーズ

「イベントループが一サイクル回る」という表現において、Loopは6つのフェーズ(Phase)を循環するという意味だ。各フェーズで非同期タスクの実行順序を決定し、その構成は次の通りだ。
- Timers:
setTimeout()、setInterval()のコールバックを実行 - Pending Callbacks: 一部のシステムI/O処理のコールバックを実行(TCPエラーなど)
- idle, prepare: 内部的な最適化処理を実行(libuv最適化)
- Poll: 待機中のI/Oイベントを確認して処理
- Check:
setImmediate()のコールバックを実行 - Close Callbacks:
socket.on('close', callback)のようなクローズイベントを実行
WebブラウザではChromiumのようなブラウザエンジンがイベントループの実装を担い、Node.jsではlibuvがこの役割を果たす。
Node.jsは公式にシングルスレッド
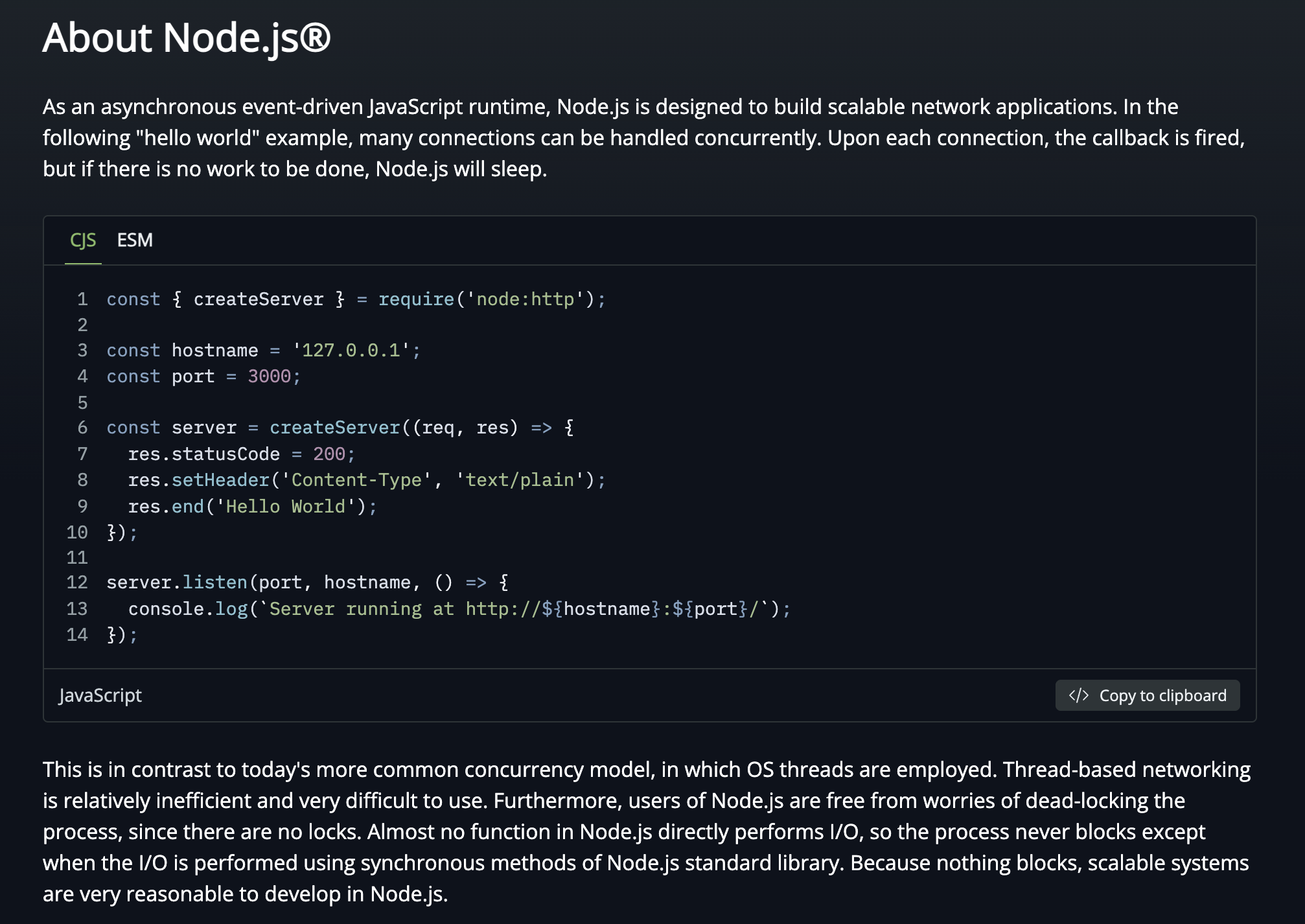
Node.js公式ドキュメント(About Node.js)を見ると、Node.jsはシングルスレッドであることを明確に打ち出している。最も決定的な証拠はNode.jsのユーザーにはLockがないという点だ。
マルチスレッド環境では、一つのリソースに同時アクセスする複数のスレッドに対してデッドロック(Deadlock)を防ぐためのスピンロック、セマフォ、ミューテックスといった同期メカニズムが必要になる。しかしNode.jsにはそういったものがない — これがNode.jsがシングルスレッドだという強力な証左だ。
ノンブロッキングとブロッキングの違いについてより詳しく知りたい場合は、Node.js公式ドキュメントのOverview of Blocking vs Non-Blockingを参照してほしい。
まとめると次のようになる。
| 観点 | 根拠 |
|---|---|
| シングルスレッド | JavaScript自体は一つのコールスタックで動作し、Lockメカニズムがない |
| マルチスレッド | libuvがスレッドプールを持ち、非同期I/Oをマルチスレッドで処理する |
どちらも間違いではない。ただしメインの実行フロー(JavaScriptコードの実行)はシングルスレッドで、非同期I/O処理を支えるlibuvはマルチスレッドというのが正確な説明だ。
シングルスレッドのアキレス腱: CPU集約的処理
Node.jsのイベントループはI/O処理には強力だが、CPU集約的処理には致命的な弱点を持っている。イベントループは一つのスレッドで動いているため、一つのタスクがCPUを長時間占有するとイベントループ自体がブロッキングされて他のすべてのリクエストが止まる。
// イベントループをブロッキングする例
app.get("/heavy", (req, res) => {
// 50億回のループ — この間、他のすべてのリクエストが待機
let sum = 0;
for (let i = 0; i < 5_000_000_000; i++) {
sum += i;
}
res.json({ result: sum });
});
app.get("/health", (req, res) => {
// /heavyが終わるまでこのリクエストも応答できない
res.json({ status: "ok" });
});
大容量JSONのパース、画像リサイズ、暗号化演算、複雑な正規表現マッチングなどが代表的なCPU集約的処理だ。こういった処理がイベントループで直接実行されると、その処理が終わるまでサーバー全体が応答不能状態に陥る。

Worker Threads: Node.jsのマルチスレッド解法
Node.js 10.5から導入されたWorker Threadsは、この問題に対する公式の解法だ。メインスレッドとは別のスレッドでJavaScriptを実行できるようにし、各Workerは独立したV8インスタンスとイベントループを持つ。
// main.js — メインスレッド
const { Worker } = require("worker_threads");
app.get("/heavy", (req, res) => {
const worker = new Worker("./heavy-task.js");
worker.on("message", (result) => {
res.json({ result }); // Workerが終わったら応答
});
worker.on("error", (err) => {
res.status(500).json({ error: err.message });
});
});
// heavy-task.js — Workerスレッド
const { parentPort } = require("worker_threads");
let sum = 0;
for (let i = 0; i < 5_000_000_000; i++) {
sum += i;
}
parentPort.postMessage(sum); // 結果をメインスレッドに送る
Worker Threadsの核心的な特徴は次の通りだ。
- 各Workerは独立したV8インスタンスを持つため、メインスレッドのイベントループをブロッキングしない
SharedArrayBufferを通じてスレッド間でメモリを共有できるpostMessage()でスレッド間のメッセージをやり取りする(WebブラウザのWeb Workerと似たパターン)- Javaのスレッドと異なり、共有リソースに対するLockは依然として不要だ — メッセージパッシング方式だからだ

Clusterモジュール: マルチコアCPUの活用
Worker Threadsが一つのプロセス内でスレッドを増やす方式なら、Clusterモジュールはアプリケーションプロセス自体を複製してマルチコアCPUを活用する方式だ。
const cluster = require("cluster");
const http = require("http");
const os = require("os");
if (cluster.isPrimary) {
const numCPUs = os.cpus().length;
console.log(`Primary process ${process.pid} is running`);
console.log(`Forking ${numCPUs} workers...`);
// CPUコア数分のWorkerプロセスを生成
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on("exit", (worker) => {
console.log(`Worker ${worker.process.pid} died. Restarting...`);
cluster.fork(); // 死んだWorkerを自動再起動
});
} else {
// 各Workerプロセスが同じポートを共有
http.createServer((req, res) => {
res.writeHead(200);
res.end(`Handled by worker ${process.pid}\n`);
}).listen(8000);
}
Clusterの動作原理は次の通りだ。
- Primaryプロセスが複数のWorkerプロセスを
fork()で生成する - 各Workerプロセスは独立したNode.jsインスタンス(V8エンジン + イベントループ)を持つ
- OSレベルで入ってくるネットワークリクエストをWorkerにラウンドロビン方式で振り分ける
- WorkerがクラッシュするとPrimaryがそれを検知して新しいWorkerを生成できる
実務ではClusterモジュールを直接使うよりPM2のようなプロセスマネージャーを使うことが多い。pm2 start app.js -i maxの一行で、CPUコア数分のプロセスを自動生成し、無停止再起動とログ管理まで処理してくれる。
| 方式 | 単位 | メモリ | 通信方式 | 主な用途 |
|---|---|---|---|---|
| Worker Threads | スレッド | 共有可能(SharedArrayBuffer) | postMessage() | CPU集約的演算 |
| Cluster | プロセス | 独立 | IPC(プロセス間通信) | マルチコア活用、水平スケーリング |
3. 非同期プログラミングパラダイムの進化
ここまでイベントループとlibuvがどのように非同期を処理するかという内部メカニズムを見てきた。では開発者はこの非同期をコードでどのように表現してきたのか。先ほどasync/awaitの動作方式を簡単に見たが、ここではJavaScriptの非同期処理方式が言語の成長とともになぜ、どのような順序で進化してきたかを整理する。
Callbacks: 出発点
JavaScriptの非同期処理の原型はコールバック関数だ。非同期処理が完了したら、あらかじめ渡しておいた関数を呼び出す方式だ。
function fetchData(callback) {
setTimeout(() => {
callback(null, { id: 1, name: "marsboy" });
}, 1000);
}
fetchData((error, data) => {
if (error) {
console.error("エラー発生:", error);
return;
}
console.log("データ:", data);
});
単純なケースでは直感的だが、非同期処理が入れ子になると、いわゆるコールバック地獄(Callback Hell)が発生する。
// コールバック地獄の例
getUser(userId, (error, user) => {
getOrders(user.id, (error, orders) => {
getOrderDetails(orders[0].id, (error, details) => {
getShippingInfo(details.shippingId, (error, shipping) => {
console.log("配送情報:", shipping);
// どんどん深くなるインデント...
});
});
});
});
コードの可読性が極端に下がり、エラー処理も各ステップで繰り返す必要があるという問題があった。
Promises: チェーニングの登場
ES6(2015)で導入されたPromiseは、コールバック地獄を解決するために登場した。非同期処理の結果を表すオブジェクトで、then()とcatch()を使ったチェーニング方式で非同期フローを制御する。
function fetchUser(userId) {
return new Promise((resolve, reject) => {
setTimeout(() => {
resolve({ id: userId, name: "marsboy" });
}, 1000);
});
}
fetchUser(1)
.then(user => getOrders(user.id))
.then(orders => getOrderDetails(orders[0].id))
.then(details => getShippingInfo(details.shippingId))
.then(shipping => console.log("配送情報:", shipping))
.catch(error => console.error("エラー発生:", error));
コールバック地獄の深いインデントが平坦化され、.catch()一つでチェーン全体のエラーを一か所で処理できるようになった。
Promiseの三つの状態は次の通りだ。
- Pending: まだ処理が完了していない状態 (
Promise { <pending> }) - Fulfilled: 処理が正常に完了した状態
- Rejected: 処理が失敗した状態
async/await: 同期コードのように書く
ES2017で導入されたasync/awaitは、Promiseベースのコードをまるで同期コードのように書けるようにする文法的糖衣(Syntactic Sugar)だ。
async function getShippingInfoForUser(userId) {
try {
const user = await fetchUser(userId);
const orders = await getOrders(user.id);
const details = await getOrderDetails(orders[0].id);
const shipping = await getShippingInfo(details.shippingId);
console.log("配送情報:", shipping);
return shipping;
} catch (error) {
console.error("エラー発生:", error);
}
}
上のコードは非同期処理であるにもかかわらず、まるで同期コードのように上から下へと順に読める。try/catchを使ったエラー処理も同期コードと同じパターンだ。

非同期パラダイムの比較
| 方式 | 導入時期 | 利点 | 欠点 |
|---|---|---|---|
| Callbacks | ES1 (1997) | シンプルで直感的 | コールバック地獄、エラー処理が複雑 |
| Promises | ES6 (2015) | チェーニング、統合エラー処理 | then()チェーンが長くなりうる |
| async/await | ES2017 | 同期的な可読性、try/catch対応 | トップレベルでの使用制限(ESMモジュールで解決) |
4. Java/Spring vs Node.js: いつ何を選ぶか
イベントループの構造、Node.jsのスレッディングモデル、非同期パラダイムの進化まで見てきた。ここで最初の問いに戻ろう。前の記事のJava/Springマルチスレッドモデルと比較すると、結局どのような状況でどのツールを選ぶべきか。
二つのモデルは根本的に異なる哲学を持っている。どちらが「より良い」かではなく、解決しようとする問題の性質によって適切なツールが異なる。
構造的差異のまとめ

| 項目 | Java/Spring | Node.js |
|---|---|---|
| 並行処理モデル | マルチスレッド (thread-per-request) | シングルスレッドイベントループ |
| I/O処理 | スレッドがブロッキングI/Oを待機 | libuvがノンブロッキング非同期で処理 |
| CPU活用 | マルチスレッドで自然にマルチコア活用 | 基本的にシングルコア、Cluster/Workerで拡張 |
| 同期化 | Lock、synchronized、セマフォなどが必要 | Lock不要(メッセージパッシング) |
| メモリ | スレッドごとにスタックメモリを割り当て | イベントループ一つで軽量 |
| エコシステム | エンタープライズ、金融、大規模システム | リアルタイムサービス、APIサーバー、MSA |
Node.jsが有利なケース
- I/O集約的サービス: チャットサーバー、リアルタイム通知、APIゲートウェイのように大量の同時接続を維持しながらDBや外部API呼び出しを多く行うサービス。スレッド一つで数万の同時接続を処理できる。
- 素早いプロトタイピング: npmエコシステムの豊富なパッケージとJavaScriptの柔軟さのおかげで、素早くMVPを作る必要があるときに有利だ。
- リアルタイム双方向通信: WebSocketベースのリアルタイムサービス(ゲームサーバー、コラボレーションツール)で、イベントループのノンブロッキング特性が際立つ。
- SSR(Server-Side Rendering): フロントエンドとバックエンドを両方JavaScriptで統一できるため、Next.jsのようなフルスタックフレームワークの基盤となる。
Java/Springが有利なケース
- CPU集約的サービス: 大容量データ処理、複雑なビジネスロジック演算、バッチ処理など。マルチスレッドでCPUコアを自然に活用する。
- エンタープライズシステム: トランザクション管理、複雑なドメインモデル、レガシーシステム連携が必要な金融・公共システムで、Springの成熟したエコシステムが強みになる。
- 型安全性が重要な大規模プロジェクト: 静的型システムとコンパイル時検証が、大規模チームでの協業とメンテナンスに有利だ。
- Virtual Threads(Java 21): Java 21の仮想スレッドは、Node.jsの強みだった軽量な並行処理をJava陣営でも使えるようにした。スレッドあたりのメモリオーバーヘッドが劇的に減り、I/O集約的サービスでもJavaの競争力が高まっている。
最近は境界が徐々に曖昧になりつつある。Node.jsはWorker ThreadsでCPU処理を行い、JavaはVirtual Threadsで軽量な並行処理を確保しながら、互いの弱点を補う方向に進化している。技術選択は「何がより良いか」ではなく「チームの能力とサービスの特性に何がより合っているか」で決めるべきだ。
まとめ
JavaScriptはウェブページの動的機能のために生まれた言語だ。生まれながらにシングルスレッドという制約を抱えてスタートしたが、イベントループとノンブロッキング非同期パラダイムという独自の方式でこの限界を乗り越えてきた。
Node.jsはこのJavaScriptをブラウザの外に持ち出し、サーバーサイドでも動作できるようにした。libuvを通じて非同期I/Oをマルチスレッドで処理しながらも、開発者にはシングルスレッドのシンプルさを維持してくれる。Lockもなくデッドロックもないため、開発者は複雑な同期問題を気にしなくていい。CPU集約的処理というアキレス腱もWorker ThreadsとClusterモジュールで補いながら、Node.jsはますます広い領域で活躍している。
前の記事で見たJava/Springのマルチスレッドモデルと、今回のNode.jsのイベントループモデルは、並行処理という同じ問題を完全に異なる方式で解いている。どちらが優れているというよりは、サービスの特性とチームの能力に合ったツールを選ぶことが最も重要だ。
1995年にBrendan Eichが10日で作ったというこの言語が、30年経った今もウェブエコシステムの中核として根付いているのは、本当に驚くべきことだ。コールバックからPromiseへ、さらにasync/awaitへと進化してきた非同期プログラミングパラダイムの発展がその証拠だ。
付録: Webブラウザの歴史
本文でV8、Chromium、WebKitといった用語が頻繁に登場した。これらのエンジンがどこから来たのか、そしてJavaScriptがなぜブラウザのためのシングルスレッド言語として生まれたのかを理解するには、Webブラウザの歴史を知っておくと良い。
1955年生まれの伝説のIT三人組とWWWの誕生
コンピューターの世界には伝説的な1955年生まれが三人いる。Microsoftのビル・ゲイツ、Appleのスティーブ・ジョブズ、そしてGoogleのエリック・シュミットが最も有名だ。ここにWWW(World Wide Web)の創始者であるティム・バーナーズ=リーを加える人もいる。
ティム・バーナーズ=リーは1989年、スイス・ジュネーブにある欧州原子核研究機構(CERN)で働いていた際、論文の参照情報を簡単につなげるシステムを考案した。これがWWWの始まりだ。ハイパーリンクを使って論文から別の論文へ直接つながれるようにすることが目的で、この過程でHTML(ハイパーテキストマークアップ言語)、HTTP(ハイパーテキスト転送プロトコル)、URL(Uniform Resource Locator)などが開発された。
驚くべきことに、ティム・バーナーズ=リーはこれらの技術を特許も取らず無償で公開した。これをきっかけに静的コンテンツを手軽に確認できるWebブラウザが誕生し始め、激しいブラウザ戦争の幕が開いた。
ブラウザ戦争: Netscape Navigator vs Internet Explorer

1990年代半ばから2000年代初頭にかけて、Netscape NavigatorとMicrosoft Internet Explorer(IE)はWebブラウザのシェアをめぐって激しく競争した。この時期はブラウザ戦争と呼ばれ、インターネットの発展とWeb技術の進化を加速させた。
1994年、Netscape CommunicationsがNetscape Navigatorをリリースし、Webブラウザ市場の制覇を始めた。コンピューターの普及が急速に進んでいた時期と重なり、約1年で80%のシェアを獲得した。
しかしインターネットの可能性に気づいたMicrosoftが、1995年のWindows 95リリースとともにInternet Explorer 1.0を発表した。Netscapeが有料でブラウザを販売していたのと異なり、IEは無料で提供され、Windowsオペレーティングシステムに統合されて一緒に配布された。OSレベルでIEを押し出した結果、1997年以降IEのシェアは急上昇し、2000年代初頭には90%以上を占めるようになった。
Netscapeの最後の一手: オープンソース

IEのシェアにもはや勝てないと判断したNetscapeは1998年、ブラウザのソースコードを公開することを決定した。こうしてWebブラウザのオープンソースが開放され、Mozilla財団がこれを引き継いでMozillaプロジェクトを開始した。
このプロジェクトから生まれたのがMozilla Firefoxだ。2002年にPhoenixという名前で開発が始まり、Firebirdを経て2004年にFirefox 1.0がリリースされた。Firefoxは最近閉じたタブを開く、セッション復元、フィッシングフィルター、音声・動画のネイティブサポートなど、当時としては革新的な機能を提供し、素早くユーザーを獲得した。
決定的だったのは2008年に登場したGoogle ChromeがIEに強烈な打撃を与えたことだ。ChromeはV8 JavaScriptエンジンを搭載して圧倒的な速度を誇り、IEは最も重くて遅いブラウザへと転落した。結局Microsoftは2022年6月15日にInternet Explorerのサポートを終了した。
レンダリングエンジンとJavaScriptエンジン

Webブラウザの内部にはレンダリングエンジンが搭載されている。HTML、CSS、JavaScriptなどを解釈して視覚的な要素として表示する役割を担う。主要なレンダリングエンジンの系譜は次の通りだ。
- WebKit: 2001年にAppleがKHTMLとKJSエンジンをベースに開発。SafariとiOS向けのすべてのブラウザに使用されている。モバイル環境に最適化されており、Appleのポリシー上iOSではWebKitの使用が必須だ。
- Blink: 2013年にGoogleがWebKitをフォーク(fork)して開発したエンジン。Chrome、Edge、Operaなどで使用されており、V8 JavaScriptエンジンとともにChromiumプロジェクトを構成する。
- Gecko: Netscapeが開発を始めた後、Mozilla財団が引き継いだオープンソースエンジン。Firefoxで使用されており、強力なWeb標準サポートとセキュリティ機能が特徴だ。
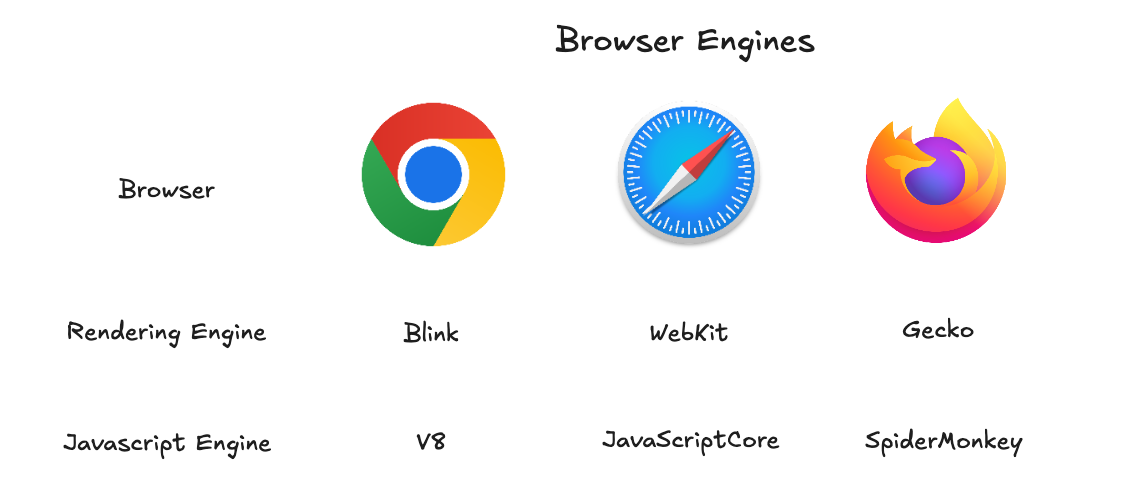
上の表からわかるようにChromeはBlink + V8、SafariはWebKit + JavaScriptCore、FirefoxはGecko + SpiderMonkeyの組み合わせを使用している。ここでよく言及されるChromiumはBlinkレンダリングエンジンとV8 JavaScriptエンジンの組み合わせを意味する。
iOSのChromeも見た目はChromiumのように見えるが、内部的にはAppleのポリシーに従いWebKitを使ってレンダリングを行っている。フロントエンド開発者がiOS環境で苦労する理由がまさにこのWebKitレンダリングエンジンの特殊性のためだ。
参考資料
- [maybe.works] The History of Web Browsers: Full Guide: https://maybe.works/blogs/browser-wars-the-history-of-browsers-and-chromium-victory
- [Node.js] Introduction to Node.js: https://nodejs.org/ko/learn/getting-started/introduction-to-nodejs
- [Evans Library] V8 엔진은 어떻게 내 코드를 실행하는 걸까?: https://evan-moon.github.io/2019/06/28/v8-analysis/
- [JSConf] What the heck is the event loop anyway?: https://www.youtube.com/watch?v=8aGhZQkoFbQ
- [BlaCk_Log] 동시성, 병렬, 비동기, 논블럭킹과 컨셉들: https://black7375.tistory.com/90
- [Alexander Zlatkov] How JavaScript works: https://medium.com/sessionstack-blog/how-does-javascript-actually-work-part-1-b0bacc073cf
- [helloinyong] Node.js가 왜 싱글 스레드로 불리는 지 “정확한 이유”: https://helloinyong.tistory.com/350