Write once, run anywhere — 一度書けば、どこでも動く。
Javaを代表するこのフレーズは、1990年代半ばから今日まで有効です。バックエンド開発者なら一度は触れることになるJavaとSpring。この記事では、Javaがなぜマルチスレッド言語なのか、Spring Bootがどのようにこれを活用して大規模トラフィックを処理するのか、そしてNode.jsとどのような構造的な違いがあるのかを整理します。
1. Javaの歴史と哲学
誕生の背景
Javaの歴史は1990年代初頭にさかのぼります。もともとOak(オーク)という名前で、Sun Microsystems(サン・マイクロシステムズ)のプロジェクトから誕生しました。このプロジェクトの本来の目的は家電製品向けの言語開発でしたが、Oakは特定のプラットフォームに限定されない汎用プログラミング言語へと発展しました。
創始者のJames Gosling(ジェームズ・ゴスリング)がコーヒー愛好家だったことから、ジャワコーヒーの産地であるJava島にちなんで名付けられました。1995年に正式発表された後、Javaは爆発的な人気を獲得しました。
JVMとバイトコード
Javaを他のコンパイル言語と区別する最大の特徴は、コンパイルされたコードがクロスプラットフォームであることです。Javaコンパイラは.javaファイルをバイトコード(bytecode)という特殊なバイナリ形式に変換し、このバイトコードを実行するためにJVM(Java Virtual Machine)が必要になります。JVMはJavaバイトコードをどのプラットフォームでも同一の形で実行します。
C言語と比較するとその違いが明確になります。
- C言語: ソースコードをコンパイルすると、CPUが直接実行できる実行ファイルが生成されます。しかし、この実行ファイルはOSとCPUアーキテクチャに依存します。Windowsでは
a.exe、macOSではa.outが生成されるといった具合です。 - Java: ソースコードをJVMが理解できるレベル(バイトコード)までのみコンパイルします。残りはJVMがインタプリティングしてアプリケーションを実行します。
このアーキテクチャにより、Javaはコンパイラとインタプリタの性質を併せ持つハイブリッド言語に分類されます。1990年代半ばにクロスプラットフォームを実現したことは、当時としては革新的なアイデアでした。
「インタプリタ方式なら遅いのでは?」という疑問を持つかもしれません。初期のJVMは実際に低速でしたが、現代のJVMにはJITコンパイラ(Just-In-Time Compiler)が搭載されています。JITコンパイラはバイトコードを実行しながら、頻繁に呼び出されるホットコード(hot code)パスを検出し、それを該当プラットフォームのネイティブコードに変換してキャッシュします。以降、同じコードが呼び出されるとインタプリティングなしでネイティブコードが直接実行されます。
これにより、Javaはランタイムで徐々に高速化するウォームアップ(warm-up)特性を持つようになり、十分にウォームアップされたJavaアプリケーションはC/C++に匹敵する実行性能を発揮できます。
Javaの現在の位置づけ
30年が経った今もJavaは健在です。JetBrainsの2024年開発者エコシステム調査によると、Javaは依然として最も広く使用されているプログラミング言語の一つであり、特にエンタープライズバックエンド領域では圧倒的なシェアを維持しています。
金融、通信、公共機関などミッションクリティカルなシステムでJavaが選ばれる理由は、その安定性、成熟したエコシステム、そして下位互換性への信頼です。Java 8で書かれたコードがJava 21でも問題なく動作するという事実は、他の言語ではなかなか見られない強みです。
Javaの5つの哲学
1991年に発表されたJavaの5つの核心哲学は以下の通りです。
- オブジェクト指向手法を用いること。
- 同じプログラム(バイトコード)が複数のオペレーティングシステムで実行できること。
- ネットワークアクセス機能がデフォルトで組み込まれていること。
- リモートコードを安全に実行できること。
- 他のオブジェクト指向言語の良い部分だけを取り入れ、使いやすくあること。
C++が1983年に発表されたことでオブジェクト指向の概念が広まり始め、1990年代にはソフトウェア工学の中核パラダイムとして定着しました。オブジェクト指向の再利用性、拡張性、保守性を備えたJavaの登場は大きな影響を与えるものでした。
この5つの哲学は、その後Javaエコシステムの発展方向を決定づける羅針盤となりました。クロスプラットフォーム(2番)はJVMが、ネットワーク機能(3番)とリモートコード実行(4番)は後に登場するServletとEJBが、そしてオブジェクト指向(1番)と利便性(5番)はSpring Frameworkがそれぞれ継承していくことになります。
JDKとJavaエディション
Javaプログラムを開発するにはJDK(Java Development Kit)が必要です。JDKはJavaコンパイラ(javac)、JVM、標準ライブラリ、デバッガなど開発に必要なツールをすべて含む開発キットです。一方、Javaプログラムを実行するだけならJRE(Java Runtime Environment)だけで十分です。JREはJVMと標準ライブラリのみを含み、JDKのサブセットです。Java 11からはJREが単独配布されなくなり、JDKに統合されました。
Javaの人気に伴い、用途に応じたさまざまなエディションが登場しました。
- Java SE(Standard Edition): JVM、コアAPI、標準ライブラリを含む基本エディションです。「JDKをインストールする」と言う場合、インストールしているのがJava SEの実装です。
- Java EE(Enterprise Edition): Java SEの上にサーバー開発に必要な技術仕様を追加したエディションです。Servlet、JSP、EJBなど、エンタープライズ環境で必要なAPIが含まれます。
- Java ME(Micro Edition): 組み込みデバイスやモバイルデバイスなど、リソースが限られた環境に特化したエディションです。
Servletとウェブ開発の革新
Javaの5つの哲学のうち3番(ネットワークアクセス機能)と4番(リモートコード実行)をウェブ開発の領域で実現したのがServletです。ServletはJava EEに含まれるサーバーサイドコンポーネントで、HTTPリクエストを受け取り、処理し、レスポンスを返すインターフェースです。Servletが登場する前は、ウェブサーバーで動的コンテンツを生成するにはCGI(Common Gateway Interface)を使用する必要がありましたが、CGIはリクエストごとに新しいプロセスを生成するという非効率的な構造でした。Servletはこれをスレッドベースに転換し、パフォーマンスと生産性の両方を向上させました。
@WebServlet(name = "helloServlet", urlPatterns = "/hello")
public class HelloServlet extends HttpServlet {
@Override
protected void service(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String username = request.getParameter("username");
response.setContentType("text/plain");
response.setCharacterEncoding("utf-8");
response.getWriter().write("hello " + username);
}
}
Java EEからJakarta EE、そしてSpringへ
ServletとEJBを中心に、Java EEはエンタープライズ開発の標準となりました。しかし、EJBは哲学こそ優れていたものの、現実は異なりました。数十行のXML設定、複雑なインターフェース実装、重いアプリケーションサーバーへの依存など、「単純なビジネスロジック一つを実装するのになぜこれほど多くのコードが必要なのか?」という不満が高まりました。
2000年代初頭、この複雑さに不満を持ったRod Johnson(ロッド・ジョンソン)が_Expert One-on-One J2EE Design and Development_という書籍を出版しました。この本で提示された軽量コンテナのアイデアがHibernateと結合し、2003年にSpring Frameworkが誕生しました。「EJBの冬の後に春が来る」という意味でSpringという名前が付けられました。
SpringはJavaの5つの哲学を継承しつつ、開発者の利便性を最大化しました。DI(依存性注入)とAOP(アスペクト指向プログラミング)を通じてオブジェクト指向の利点を活かしながら、ボイラープレートコードを大幅に削減しました。また、内部的にServletを活用しつつも、開発者がServlet APIを直接扱う必要なく、@Controllerや@RequestMappingといったアノテーションでウェブ開発ができるよう抽象化しました。
一方、Sun Microsystemsが2010年にOracleに買収された後、Java EEの発展方向に対するコミュニティの懸念が高まりました。最終的にOracleは2017年にJava EEをEclipse Foundationに移管することを決定し、商標権の問題からJakarta EEという名前に変更されました。これにより、コミュニティ主導のオープンソース開発が本格化しました。
2. Springのマルチスレッドアーキテクチャ
プロセスとスレッドの基礎
Springのマルチスレッドを理解するには、まずプロセスとスレッドの概念を押さえる必要があります。
プログラムはディスクに保存されたデータであり、これを実行するとメモリにロードされてプロセスになります。CPUはメモリ上のさまざまなプロセスを高速に切り替えながら実行することで、複数のプロセスが同時に動いているように見せています。

プロセスはcode、data、heap、stackの4つの領域で構成されます。

各領域の役割は以下の通りです。
- Code: コンパイルされたプログラムの命令(マシンコード)が格納される領域です。読み取り専用で、プロセスが実行するすべての関数とロジックがここに配置されます。
- Data: グローバル変数と
static変数が格納される領域です。プログラム開始時に割り当てられ、終了まで維持されます。 - Heap:
newキーワードなどで動的に割り当てられるメモリ領域です。開発者がランタイムに必要な分だけメモリを要求し、使用後に解放します。JavaではGC(ガベージコレクタ)がこの解放を自動的に処理します。 - Stack: 関数呼び出し時に生成されるローカル変数、パラメータ、リターンアドレスなどが格納される領域です。関数が呼び出されるたびにスタックフレームが積まれ、関数が返るとそのフレームが除去されます。
ダイアグラムでは、メモリアドレスが上部を0xFFFFFFFF(高いアドレス)、下部を0x00000000(低いアドレス)として表記されています。これはOSがプロセスに付与する仮想メモリアドレス空間を表しています。32ビットシステムの場合、各プロセスは0から約4GB(0xFFFFFFFF)までのアドレス空間を持ちます。
ここでの重要な設計がHeapとStackの成長方向です。Heapは低いアドレスから高いアドレスの方向(↓)に、Stackは高いアドレスから低いアドレスの方向(↑)に成長します。2つの領域が互いに反対方向に拡張するため、その間の空き領域(free space)を最大限効率的に活用できます。もし2つの領域が同じ方向に成長すると、一方が溢れた際にもう一方の余裕空間を活用できなくなります。この設計のおかげで、HeapとStackは互いの余裕空間を共有しながら柔軟にメモリを使用できます。
シングルスレッド vs マルチスレッド
スタックが1つのプロセスをシングルスレッド(single thread)と呼びます。スレッド(thread)とはプロセス内のより小さな実行単位のことです。
マルチスレッド(multi thread)は、1つのプロセス内に複数のスタックを配置し、さまざまな作業を同時に処理しているかのように見せる仕組みです。ポイントはcode、data、heap領域をスレッド間で共有するということです。このため、シングルスレッドのプロセスを複数起動するよりもオーバーヘッドが少なくなります。

しかし、マルチスレッドには致命的な制約があります。複数のスレッドが共有データに同時にアクセスして値を変更しようとすると、同時実行の問題(Concurrency Problem)が発生します。簡単な例を見てみましょう。
public class Counter {
private int count = 0;
public void increment() {
count++; // read → modify → write: この3ステップはアトミックではない
}
public int getCount() {
return count;
}
}
2つのスレッドが同時にincrement()を呼び出すと、両方が同じ値を読み取って1を加えて保存し、結果的に1しか増加しないという競合状態(Race Condition)が発生する可能性があります。synchronizedキーワードでこれを防ぐことができます。
public class Counter {
private int count = 0;
public synchronized void increment() {
count++; // 一度に1つのスレッドのみ実行可能
}
public synchronized int getCount() {
return count;
}
}
synchronized以外にも、スピンロック(Spinlock)、セマフォ(Semaphore)、java.util.concurrentパッケージのAtomicIntegerなど、さまざまな同期メカニズムが提供されています。
Springでの落とし穴: Springのデフォルトのビーンスコープはシングルトン(Singleton)です。つまり、すべてのリクエストスレッドが同じビーンインスタンスを共有します。したがって、ビーンに状態(インスタンス変数)を持たせると、上記と同じ同時実行の問題が発生します。Springのビーンは常にステートレス(stateless)で設計すべきです。
// BAD - シングルトンビーンに状態を保存するとスレッド間でデータが壊れる
@Service
public class OrderService {
private int todayOrderCount = 0; // すべてのスレッドで共有!
public void placeOrder() {
todayOrderCount++; // Race Condition 発生
}
}
// GOOD - 状態はDBや外部ストレージに委譲
@Service
public class OrderService {
private final OrderRepository orderRepository;
public void placeOrder(Order order) {
orderRepository.save(order); // DBのトランザクションが同時実行を管理
}
}
Javaのマルチスレッド実装
Javaは言語レベルで2つの方法でマルチスレッドをサポートしています。
Threadクラスの継承方式:
public class MyThread extends Thread {
public void run() {
System.out.println("Thread実行!");
}
}
new MyThread().start();
Runnableインターフェースの実装方式:
public class MyRunnable implements Runnable {
public void run() {
System.out.println("Runnable実行!");
}
}
new Thread(new MyRunnable()).start();
マルチスレッドを直接実装する場合は、Lockとsynchronizedキーワードを使って同期を手動で管理する必要があります。しかし、Spring Bootではスレッドプール(Thread Pool)の概念により、これをはるかに便利に扱えます。
Tomcatのスレッドプール
スレッドプール(Thread Pool)は、マルチスレッドを効率的に管理するためにスレッドを事前に生成しておくプールです。新しいタスクが要求されると、プール内のアイドルスレッドがタスクを実行し、タスクが完了するとスレッドはプールに返却されます。これにより、スレッドの生成・破棄のオーバーヘッドを削減し、レスポンスタイムを短縮できます。
Spring Bootにおけるスレッドプール管理は、正確にはSpring Boot自体ではなく、内蔵されたTomcat(サーブレットコンテナ)が担当しています。

このダイアグラムで中核的な役割を果たすのがDispatcherServletです。Spring MVCのフロントコントローラ(Front Controller)パターンを実装したもので、すべてのHTTPリクエストを単一のエントリーポイントで受け取り、適切なControllerにルーティングします。開発者がURLごとにサーブレットをマッピングする必要なく、@RequestMappingアノテーションだけでリクエスト処理を定義できるのは、DispatcherServletのおかげです。

TomcatはHTTPリクエストを処理するサーブレットコンテナです。複雑なHTTP Requestの構造を開発者の代わりにパースしてくれます。
初期のTomcat(3.2以前)では、リクエストごとにスレッドを新規生成し、処理後に破棄していました。同時多発的なリクエストに対して毎回スレッドを生成することは大きな負荷を招いたため、スレッドを事前に生成してプールに保管する方式に移行しました。

HTTP Requestが到着するとキューにタスクが渡され、アイドル状態のスレッドがタスクを割り当てられます。application.yamlでスレッドプールを設定できます。
server:
tomcat:
threads:
max: 200 # 生成可能なスレッドの総数
min-spare: 10 # 常にアクティブな(アイドル)スレッドの数
accept-count: 100 # タスクキューのサイズ
デフォルトでは最大200個のスレッドを生成でき、最低10個のアイドルスレッドを維持します。タスクキューには最大100個の待機タスクを保管できます。これらの値はCPU使用率とリクエストパターンに応じて適切に調整する必要があります。
HikariCPコネクションプール
サーブレットコンテナであるTomcatがリクエスト自体をマルチスレッドで処理することがわかりました。では、データベースとの接続はどのように処理されるのでしょうか?
DBにデータを読み書きするたびにコネクションを新たに生成すること自体が大きなオーバーヘッドとなります。これを解決するために、スレッドプールと同じ発想でコネクションプール(Connection Pool)を使用します。コネクションを事前に作成しておき、必要なときに使い回すのです。
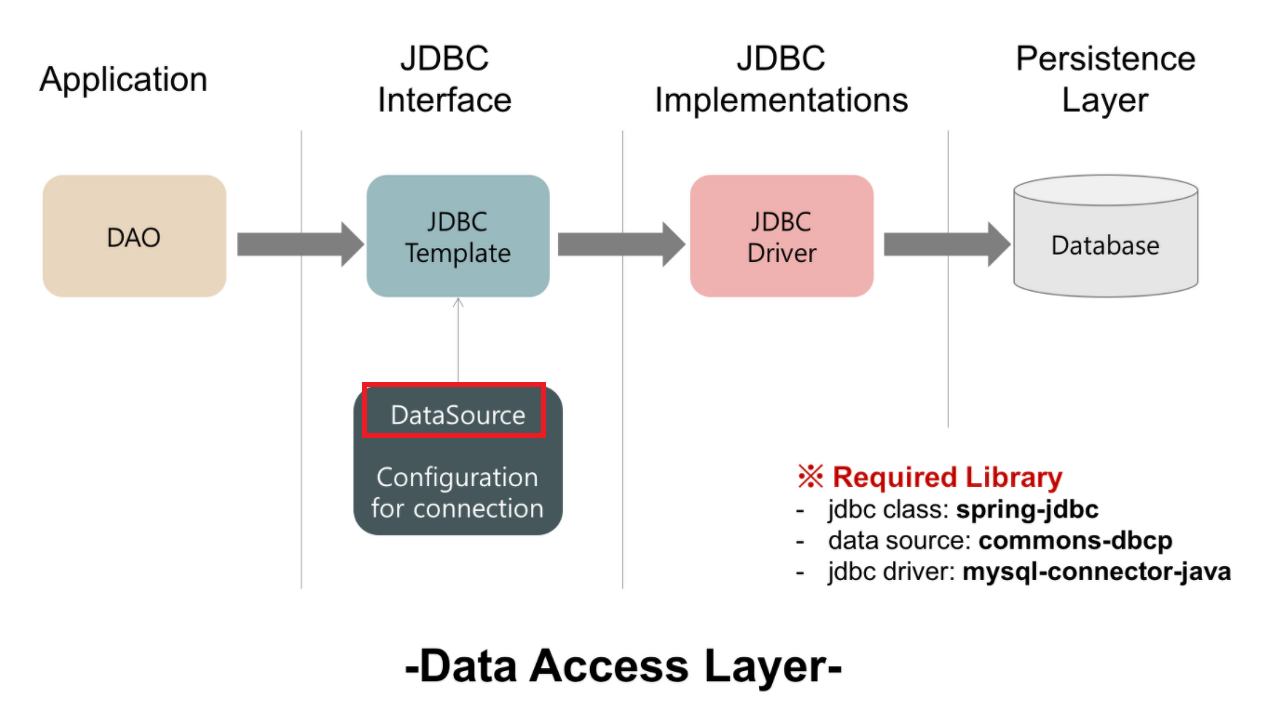
Spring陣営でデータベース接続に使用する標準インターフェースがJDBC(Java Database Connectivity)です。Spring Boot 2.0からはHikariCPがデフォルトのコネクションプールとして採用されています。application.yamlで以下のように設定します。
spring:
datasource:
url: jdbc:mysql://localhost:3306/mydb
username: myuser
password: mypassword
hikari:
maximum-pool-size: 10 # 最大コネクション数
connection-timeout: 5000 # コネクション取得待ち時間(ms)
connection-init-sql: SELECT 1
validation-timeout: 2000 # コネクション検証時間(ms)
minimum-idle: 10 # 最小アイドルコネクション数
idle-timeout: 600000 # アイドルコネクション保持時間(ms)
max-lifetime: 1800000 # コネクションの最大寿命(ms)
マルチスレッド環境で同時にデータを書き込む際に発生する同時実行の問題は、HikariCPとデータベースのトランザクションメカニズムが処理してくれます。
まとめると、Spring Bootがマルチスレッドアプリケーションと呼ばれる理由は以下の通りです。
- Tomcatスレッドプール: HTTPリクエストをマルチスレッドで処理
- HikariCPコネクションプール: DB I/Oをマルチスレッドで処理
- JVM: JavaのThreadクラスとバイトコード実行自体をマルチスレッドで管理
このパイプライン全体が最初から最後までマルチスレッドで動作しているのです。
Virtual Threads: Java 21のゲームチェンジャー
従来のJavaスレッドは、OSスレッドと1:1でマッピングされるプラットフォームスレッド(Platform Thread)です。OSスレッドは生成コストが高く(約1MBのスタックメモリ)、数千個以上生成するとコンテキストスイッチングのオーバーヘッドが急激に増加します。これがスレッドプールを使用する根本的な理由です。
Java 21で正式導入されたVirtual Threads(仮想スレッド)は、この限界を根本的に解決します。JVMが管理する軽量スレッドで、OSスレッドの上に多数の仮想スレッドをマッピングするM:Nスレッディングモデルを使用します。
// 従来のプラットフォームスレッド
Thread platformThread = new Thread(() -> {
System.out.println("Platform Thread");
});
// Virtual Thread - 生成コストが極めて低い
Thread virtualThread = Thread.ofVirtual().start(() -> {
System.out.println("Virtual Thread");
});
// 数百万のVirtual Threadも可能
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
for (int i = 0; i < 1_000_000; i++) {
executor.submit(() -> {
Thread.sleep(Duration.ofSeconds(1));
return "Done";
});
}
}
Virtual Threadの核心は、ブロッキングI/O時にOSスレッドを占有しないということです。I/O待機状態に入ると、JVMが該当仮想スレッドをOSスレッドからアンマウント(unmount)し、別の仮想スレッドをその場所にマウントします。これにより、スレッドプールサイズの制約なく同時実行性を最大化できます。
Spring Boot 3.2からは、設定1行でTomcatのリクエスト処理をVirtual Threadベースに切り替えることができます。
spring:
threads:
virtual:
enabled: true
この設定だけで、既存の同期ブロッキングコードを修正することなくスループットを大幅に向上させることができます。
Spring WebFlux: リアクティブな代替手段
Virtual Threads以前に、Spring陣営で高い同時実行性を達成するためのアプローチがSpring WebFluxでした。Node.jsと類似したノンブロッキングリアクティブモデルをJava/Springで実装したものです。
@GetMapping("/users/{id}")
public Mono<User> getUser(@PathVariable String id) {
return userRepository.findById(id); // ノンブロッキング戻り値
}
WebFluxはNettyベースで動作し、イベントループパターンを使用します。少ないスレッドで高いスループットを達成できますが、リアクティブプログラミングの学習曲線が急で、既存のJDBCベースのライブラリとの互換性の問題がありました。
Virtual Threadsの登場により、従来の慣れ親しんだ同期コードスタイルを維持しながらもWebFluxに匹敵する同時実行性を達成できるようになりました。このため、新規プロジェクトではまずVirtual Threadsを検討し、ストリーミングやバックプレッシャー制御が必要な場合にのみWebFluxを選択するのが現在のトレンドです。
3. Node.js vs Java/Spring: 構造的比較
Node.jsとJava/Springは同時実行処理の方式で根本的な違いがあります。
Node.js: シングルスレッドイベントループ
Node.jsはシングルスレッドイベントループモデルを使用します。1つのメインスレッドがイベントループを回しながら、受信リクエストを処理します。I/O操作(ファイル読み取り、DBクエリ、ネットワークリクエストなど)は非同期(non-blocking)で処理され、I/O完了時にコールバックがイベントキューに登録され、イベントループがこれを処理します。

ただし、「シングルスレッド」という表現はイベントループに限った話です。Node.js内部にはlibuvというCライブラリがあり、ファイルシステムI/OやDNS検索などOSレベルで非同期をサポートしていない操作はlibuvのスレッドプール(デフォルト4個)で処理されます。ネットワークI/OはOSのepoll/kqueueを活用するためスレッドプールを経由しません。つまり、Node.jsは開発者にシングルスレッドモデルを提供しつつ、内部的には必要な箇所でマルチスレッドを活用する構造になっています。
Java/Spring: マルチスレッドプール
Java/Springはマルチスレッドプールモデルを使用します。Tomcatが管理するスレッドプールから、各リクエストに別々のスレッドを割り当てて処理します。各スレッドはリクエストの開始からレスポンスまで同期的(blocking)に処理するのがデフォルトです。

比較まとめ
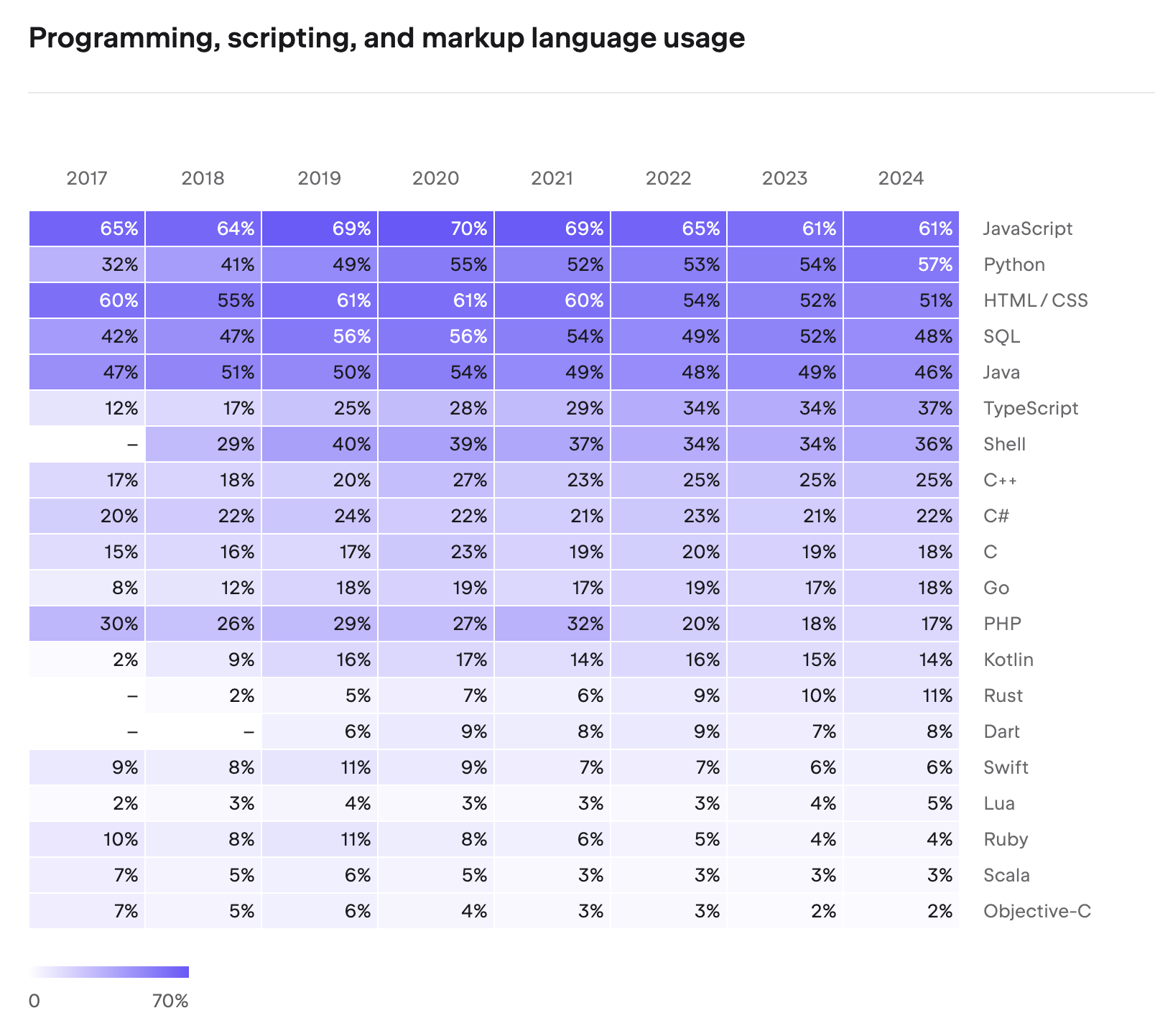
| 項目 | Node.js | Java/Spring |
|---|---|---|
| スレッディングモデル | シングルスレッドイベントループ | マルチスレッドプール(Tomcat) |
| I/O処理 | 非同期ノンブロッキング | 同期ブロッキング(デフォルト) |
| 同時実行の実装 | イベントループ + コールバック/Promise | スレッドプール + 同期メカニズム |
| CPU集約的タスク | メインスレッドブロッキングのリスク | 別スレッドで並列処理可能 |
| メモリ使用量 | 比較的少ない | スレッドごとのメモリ割り当てが必要 |
| DB接続 | 非同期ドライバー | HikariCPコネクションプール |
| スケーリング方式 | クラスタモジュール(プロセス複製) | スレッドプールサイズの調整 |
各モデルの強み
Node.jsの強み:
- I/Oバウンドなワークロードで高いスループット
- 少ないメモリで多数の同時接続を処理可能
- 簡潔な非同期コード(async/await)
- リアルタイムアプリケーション(チャット、ストリーミング)に最適
Java/Springの強み:
- CPU集約的タスクでの真の並列処理
- 成熟した同時実行制御メカニズム(synchronized、Lock、Concurrentパッケージ)
- 大規模エンタープライズシステムでの実証された安定性
- スレッド単位の直感的なデバッグとスタックトレース
大規模トラフィック処理はSpring Bootが最も得意とするところです。
こうした声をよく耳にするのには理由があります。JVMのマルチスレッドサポート、Tomcatのスレッドプール、HikariCPのコネクションプールが有機的に結合し、高いスループットと安定性を保証しているからです。
4. まとめ
Javaは30年間「Write Once, Run Anywhere」という哲学を守り続け、その上に構築されたSpringエコシステムはエンタープライズバックエンドのデファクトスタンダードとなりました。
この記事で取り上げた要点をまとめると以下の通りです。
- JVMのバイトコード + マルチスレッドサポートがJavaの基盤である。
- TomcatスレッドプールがHTTPリクエストを、HikariCPコネクションプールがDB I/Oをマルチスレッドで処理することで、Spring Bootの高いスループットを実現している。
- Virtual Threads(Java 21)はOSスレッドの限界を超えて同時実行性を最大化する新しいパラダイムである。
- Node.jsのシングルスレッドイベントループとJava/Springのマルチスレッドプールにはそれぞれの強みがあり、ワークロードの特性に応じて正しい選択は異なる。
技術選択に正解はありません。重要なのは、各技術がなぜそのように設計されたのかを理解し、解決すべき問題に合ったツールを選ぶことです。
参考資料
- [Oracle] Introduction to Java: https://www.oracle.com/java/technologies/introduction-to-java.html
- [Wikipedia] Java(プログラミング言語): https://ko.wikipedia.org/wiki/자바_(프로그래밍_언어)
- [JetBrains] The State of Developer Ecosystem 2023: https://www.jetbrains.com/lp/devecosystem-2023/
- [velog] Spring Bootはどのように複数リクエストを処理するのか?: https://velog.io/@sihyung92/how-does-springboot-handle-multiple-requests
- [velog] Spring DBコネクションプールとHikari CP: https://velog.io/@miot2j/Spring-DB커넥션풀과-Hikari-CP-알아보기
- [Gradle] Gradle vs Maven Performance: https://gradle.org/gradle-vs-maven-performance/
- [JEP 444] Virtual Threads: https://openjdk.org/jeps/444
- [Spring Blog] Spring Boot 3.2 Virtual Threads: https://spring.io/blog/2023/09/09/all-together-now-spring-boot-3-2-graalvm-native-images-java-21-and-virtual