前回の記事では、CNIがPodにIPを付与し、ノード間通信を可能にするメカニズムを扱った。veth pair、ブリッジ、VXLANカプセル化 — 結局、OSのネットワークプリミティブを組み合わせて「フラットなL3ネットワーク」という幻想を作り上げるものだった。
今回の記事では、そのネットワークの上に何をさらに積み重ねれば数百のサービスが安全に、観測可能に、宣言的に通信できるのかを掘り下げる。Istioがiptablesでトラフィックを透過的にインターセプトする方法、EnvoyにxDSで設定を配信する構造、mTLSでZero Trustを実現する原理まで — サービスメッシュの内部動作をカーネルレベルから追っていく。

今回の記事に関連するネットワークシリーズの投稿は以下の通りだ。
全体アーキテクチャ:Control Plane + Data Plane
Istioは、Kubernetes上でサービス間のトラフィック管理、セキュリティ(mTLS)、オブザーバビリティを提供するオープンソースのサービスメッシュだ。アプリケーションコードを修正せずにこれらすべての機能を透過的に適用できるというのが核心だ。
ネットワークを説明する観点からIstioを分解すると、大きく2つに分けられる。
Control Plane(istiod)
中央管理者。Pilot、Citadel、Galleyが一つに統合されたコンポーネントで、Envoyプロキシに設定を配信する役割を担う。Kubernetes APIをwatchしながらService、Endpoint、VirtualServiceなどのリソース変更を検知し、Envoyが理解できるxDS(discovery service)設定に変換して各サイドカーにpushする。
Data Plane(Envoyプロキシ)
実際にトラフィックが流れる場所。すべてのPodにサイドカーとしてインジェクトされたEnvoyがトラフィックをインターセプトして処理する。

上の図をもう少し詳しく説明すると、PodにApp Containerが起動する際、istio-proxyというサイドカーコンテナが一緒に起動する。istio-proxyは内部的にEnvoyプロキシを実行しながらブートストラップと証明書管理ロジックを追加したものなので、「Envoy」と「istio-proxy」は事実上同じものを指す。
Pod AからPod Bにリクエストを送ると、アプリが直接Pod Bと通信するわけではない。Linuxカーネルのnetfilterがiptablesルールを通じてトラフィックをインターセプトし、istio-proxyに転送する。具体的には、アウトバウンドトラフィックはOUTPUTフックで、インバウンドトラフィックはPREROUTINGフックでそれぞれEnvoyのリスニングポート(15001、15006)にREDIRECTされる。結果として、アプリは互いに直接通信していると思っているが、実際には両側のistio-proxy同士が通信している構造だ。
この過程で、istio-proxy同士はmTLS(Mutual TLS)で暗号化されたチャネルを確立する。通常のTLSではサーバーだけが証明書を提出するのに対し、mTLSではクライアントも証明書を提出して双方が互いの身元を暗号学的に検証する。そしてこれらすべてのネットワーク設定 — ルーティングルール、証明書、セキュリティポリシー — は上位のistiodがxDSというプロトコルを通じてgRPCストリームで各istio-proxyにリアルタイムで配信する。
サイドカーインジェクションの仕組み:Mutating Admission Webhook
Kubernetes API Serverのリクエスト処理パイプライン
kubectl applyでPodを作成すると、そのリクエストはAPI Serverに到達した後、保存される前にいくつかの段階を経る:
kubectl apply(Pod作成リクエスト)
│
▼
Authentication(認証:お前は誰だ?)
│
▼
Authorization(認可:お前にこの操作の権限はあるか?)
│
▼
Mutating Admission Webhooks ← ★ ここでPod specを「変形」できる
│
▼
Schema Validation(スキーマ検証)
│
▼
Validating Admission Webhooks ← 変形はできず、拒否のみ可能
│
▼
etcdに保存 → Pod作成が進行
Mutating Admission Webhookはこのパイプラインの途中に割り込んで「リクエスト内容を修正(mutate)できる外部HTTPエンドポイント」だ。API ServerがPod作成リクエストを受け取ると、登録されたwebhookサーバーにそのリクエストを送り、webhookサーバーが「このPod specにこのコンテナを追加してくれ」というJSON Patchをレスポンスとして返す構造だ。

上の図はIstioを使用している状況でのMutating Admission Webhookだ。
Istioの場合の具体的な動作
Istioをインストールすると、istiodは自分自身をMutating Admission WebhookとしてAPI Serverに登録する。この際、「ネームスペースにistio-injection=enabledラベルがある場合にのみ呼び出してくれ」という条件を一緒に付ける。
# MutatingWebhookConfiguration(簡略化)
apiVersion: admissionregistration.k8s.io/v1
kind: MutatingWebhookConfiguration
metadata:
name: istio-sidecar-injector
webhooks:
- name: sidecar-injector.istio.io
clientConfig:
service:
name: istiod # webhookサーバー = istiod
namespace: istio-system
path: /inject # このパスにリクエストが送られる
namespaceSelector:
matchLabels:
istio-injection: enabled # このラベルがあるネームスペースのみ
rules:
- operations: ["CREATE"]
resources: ["pods"] # Pod作成時のみ動作
インジェクションの流れ
istio-injection=enabledラベルが付いたネームスペースでPod作成リクエストが来る- API Serverが「このネームスペースにマッチするwebhookがあるな」とistiodの
/injectエンドポイントにPod specを送る - istiodがPod specを受け取り、2つのコンテナを追加するJSON Patchをレスポンス:
- istio-init(initコンテナ)— 起動時にiptablesルールを設定する役割
- istio-proxy(サイドカーコンテナ)— Envoyプロキシ本体
- API Serverがそのpatchを適用して修正されたPod specをetcdに保存
- kubeletが修正されたspec通りにPodを起動 → サイドカーが一緒に起動
核心は、アプリ開発者がDeployment YAMLにEnvoy関連の設定を一切書かなくても、webhookが自動的に挿入するということだ。
Mutating Admission WebhookはIstio固有のメカニズムではない。Kubernetesエコシステムで同じパターンを使うサービスは数多い:
- Vault Agent Injector — Pod作成時に
vault.hashicorp.com/agent-inject: "true"アノテーションを検知してVault Agentサイドカーをインジェクトする。アプリがシークレットを直接取得する必要がなく、サイドカーがVaultからシークレットを取得してファイルとしてマウントする。 - Linkerd — Istioと同じサービスメッシュだが、より軽量なアプローチ。
linkerd.io/inject: enabledアノテーションでlinkerd-proxyサイドカーをインジェクトする。 - AWS App Mesh Controller — EKS環境でEnvoyサイドカーを自動インジェクトしてAWS App Meshに接続する。
- Cert-manager — Mutating WebhookでPodやIngressにTLS証明書関連の設定を自動的に付与する。
パターンは同じだ — 特定のラベルやアノテーションをトリガーとして、Pod specがetcdに保存される前に目的のコンテナや設定を挿入すること。
似た例としてPrometheusもアノテーション(prometheus.io/scrape: "true")を付けて設定するが、動作方式は根本的に異なる。
- Istio Mutating Webhook → Pod spec自体を変形する。サイドカーを挿入する方式。(Push)
- Prometheusアノテーション → Podは変わらない。「ここにいるから収集しに来てくれ」というヒントを残す方式。(Pull)
どちらもラベル/アノテーションというメタデータをトリガーに自動化が動作するという共通点があるが、一方はPodを直接修正し、もう一方は外部から読み取るだけだ。
トラフィックインターセプトの核心:iptablesリダイレクト
istio-initコンテナが設定するiptablesルールのコアロジック:
# 1. ISTIO_REDIRECTチェーン作成 — すべてのトラフィックをEnvoyの15001ポートに送る
iptables -t nat -N ISTIO_REDIRECT
iptables -t nat -A ISTIO_REDIRECT -p tcp -j REDIRECT --to-ports 15001
# 2. ISTIO_IN_REDIRECT — インバウンドトラフィックをEnvoyの15006ポートへ
iptables -t nat -N ISTIO_IN_REDIRECT
iptables -t nat -A ISTIO_IN_REDIRECT -p tcp -j REDIRECT --to-ports 15006
# 3. OUTPUTチェーン — Podから出るトラフィックをインターセプト
iptables -t nat -A OUTPUT -p tcp -j ISTIO_OUTPUT
# 4. PREROUTINGチェーン — Podに入るトラフィックをインターセプト
iptables -t nat -A PREROUTING -p tcp -j ISTIO_INBOUND
netfilterの5つのフックポイントのうち、PREROUTINGとOUTPUTが使用される。natテーブルのREDIRECTターゲットを使って、宛先ポートをEnvoyがリッスンしているポートに書き換える構造だ。

無限ループの防止
ここで一つ問題が生じる。Envoyも結局、同じPod内でトラフィックを送信するプロセスだ。EnvoyがOUTPUTフックに捕捉されて自分自身にREDIRECTされると、無限ループに陥る。
解決策はシンプルだ。istio-proxyコンテナはUID 1337で実行されるように固定されており、iptablesルールで--uid-owner 1337からの送信トラフィックはRETURN(インターセプトをスキップ)する。つまり「UID 1337が送ったパケットなら → すでにEnvoyが処理したトラフィックだからそのまま通せ」ということだ。
# Envoy(UID 1337)が送るトラフィックはインターセプトしない
iptables -t nat -A ISTIO_OUTPUT -m owner --uid-owner 1337 -j RETURN
元の宛先の復元:SO_ORIGINAL_DST
iptables REDIRECTはパケットの宛先アドレスを127.0.0.1:15001に書き換えてしまう。ではEnvoyは、このパケットが元々どこに向かおうとしていたのかをどうやって知るのか?
Linuxカーネルのconntrack(connection tracking)がその答えだ。conntrackはNAT変換を行う際に、元の宛先情報をカーネル内部に記録しておく。EnvoyはソケットにSO_ORIGINAL_DSTオプションを使ってこの情報を照会すれば、REDIRECT前の元の宛先IPとポートを復元できる。
結局、Istioのトラフィックインターセプトはnetfilterフック → iptables nat REDIRECT → conntrackの元の宛先記録 → SO_ORIGINAL_DSTによる復元というLinuxカーネルネットワークスタックの機能を組み合わせた構造だ。
実際のリクエストフロー(Pod A → Pod B)

アプリの立場からすると、Pod Bに直接リクエストを送って直接レスポンスを受け取ったように感じる。しかし実際は異なる — すべてのトラフィックはOUTPUTとPREROUTINGフックを通じて、アプリに届く前にEnvoyが先に受け取って処理する。詳細なステップは以下の通りだ。
- App Container(Pod A) — アプリがPod BのService IP:Portに
connect()を呼び出す - OUTPUTフック — netfilterがISTIO_OUTPUTチェーンでマッチし、宛先を
127.0.0.1:15001(Envoy outbound)にREDIRECT - Envoyサイドカー(Pod A) —
SO_ORIGINAL_DSTで元の宛先を復元し、xDS設定に従ってルーティング決定(ロードバランシング、リトライ、タイムアウトなど)。istiodが発行した証明書でmTLSハンドシェイクを開始し、Pod Bの実際のIPに新しい接続を作成 - PREROUTINGフック — Pod Bに到着したトラフィックをISTIO_INBOUNDチェーンで
127.0.0.1:15006(Envoy inbound)にREDIRECT - Envoyサイドカー(Pod B) — mTLS検証、AuthorizationPolicyチェック、メトリクス収集の後、localhostを通じてアプリポートに転送
- App Container(Pod B) — アプリがリクエストを受信。アプリの立場からは直接受け取ったように見える
核心:アプリは相手のアプリと直接通信していると思っているが、実際には両側のEnvoy同士が通信している。 この構造のおかげで、アプリコードを一切修正せずにmTLS、リトライ、メトリクス収集などが透過的に動作する。
Envoyが提供する機能
このサイドカー構造のおかげで、アプリコード修正なしに:
- トラフィック管理 — VirtualService、DestinationRuleで重み付きルーティング、カナリーデプロイ、サーキットブレーカー、リトライ、タイムアウトを宣言的に設定
- セキュリティ — Pod間通信が自動的にmTLSで暗号化。PeerAuthentication、AuthorizationPolicyでL7レベル(HTTPパスやメソッドまで)のアクセス制御
- オブザーバビリティ — すべてのリクエストのレイテンシ、成功率、スループットを自動収集してPrometheusメトリクスとして公開、分散トレーシングヘッダーの伝播、アクセスログ
Pilot、Citadel、Galley → istiod統合
Istioの初期バージョン(1.4以前)では、Control Planeが別々の3つのマイクロサービスに分離されていた。
Pilot — トラフィック管理の頭脳
「Envoyにトラフィックをどうルーティングするかを教える役割。」
KubernetesのService、Endpoint、そしてIstioのVirtualService、DestinationRuleといったリソースをwatchしながら、この情報をEnvoyが理解するxDS API(LDS、RDS、CDS、EDS)に変換して各サイドカーにgRPCストリームで配信する。Envoyが「このリクエストはどこに送ればいい?」「リトライは何回?」「タイムアウトは?」を知っているのは、すべてPilotが配信した設定のおかげだ。
Citadel — セキュリティ担当(証明書管理)
「サービス間mTLSに使われる証明書を発行・更新するCA(Certificate Authority)。」
各Envoyサイドカーは起動時にCitadelに自分のサービスIDに対応するX.509証明書を要求し、Citadelが署名して返す。この証明書があってはじめて、Pod AのEnvoyとPod BのEnvoyがmTLSハンドシェイクを行える。証明書の期限切れ前の自動更新もCitadelが担当していた。
Galley — 設定の検証と配布
「ユーザーが作成したIstio設定(VirtualService、DestinationRuleなど)を検証し、正規化して他のコンポーネントに配布する中間層。」
設定が正しいかチェックし、内部フォーマットに変換するプリプロセッサの役割だった。他のコンポーネントがKubernetes APIを直接叩く部分をGalleyが抽象化しようとしていた。
なぜ統合されたか → istiod
この3つが別々に動いていて生じた問題:
- 運用の複雑さ — 3つのDeploymentをそれぞれデプロイ、モニタリング、スケーリングする必要があった
- コンポーネント間通信 — 互いにネットワークで通信するため障害ポイントが増加
- リソースオーバーヘッド — それぞれが別プロセスとしてメモリとCPUを消費
- Galleyの存在意義 — 実際にはPilotがKubernetes APIを直接watchする方が効率的で、Galleyの抽象化層はむしろ複雑さを追加するだけだった
Istio 1.5からこの3つの機能を一つのバイナリistiodに統合:
istiod = Pilot(トラフィック設定配布)
+ Citadel(証明書発行/更新)
+ Galley(設定検証)
機能は同じだが一つのプロセスで動く。istiodの「d」はUnix伝統のdaemonネーミングだ(sshd、httpdのように)。

Before(Istio < 1.5):
- 3つの別々のDeploymentを管理する必要があった
- コンポーネント間のネットワーク呼び出しが必要
- Galleyが不要な複雑さを追加
After(Istio >= 1.5):
- 単一Deploymentで運用が簡便
- プロセス内呼び出しでネットワークオーバーヘッドを排除
- リソース使用量が削減
EnvoyとIstioの関係
ここまでEnvoyとistio-proxyを混用してきたが、この2つの関係を正確に整理しておこう。
Envoyは独立したプロジェクトだ
EnvoyはIstioの一部ではない。 もともとLyftで作られた独立したオープンソースプロキシで、現在はCNCF graduatedプロジェクトだ。Istioが登場する前から存在しており、Istioなしでも単独で使える。
Envoy単体でできること:
- L7プロトコル認識(HTTP/1.1、HTTP/2、gRPC、TCP、MongoDB、Redisなど)
- ロードバランシング(Round Robin、Least Request、Ring Hashなど)
- サーキットブレーカー、リトライ、タイムアウト
- TLS termination / origination
- オブザーバビリティ(メトリクス、トレーシング、アクセスログ)
- 動的設定変更(再起動なしにxDS APIを通じて)
最後のポイントが核心だ — Envoyは設定を外部から動的にインジェクトできるようにxDSというAPIインターフェースを提供している。
Istioは何をするのか?
Envoyは単体でも強力だが、数十〜数百のEnvoyを誰が管理するかという問題がある。Podが100個ならEnvoyも100個で、それぞれに設定変更を通知する必要がある。Istioはまさにこの管理問題を解決するControl Planeだ。
例え:
- Envoy = 各交差点に立つ交通警察。直接車両(パケット)を制御する能力がある。
- Istio(istiod) = 中央交通管制センター。すべての交通警察にリアルタイムで指示を出す。
istio-proxy = Envoy + α
kubectl describe podで見えるistio-proxyコンテナはEnvoyバイナリ + Istioが追加したブートストラップロジックだ。
istio-proxyコンテナ内で動いているもの:
1. pilot-agent(Istioが作ったラッパー)
├── Envoyプロセスを起動・管理
├── istiodから初期ブートストラップ設定を取得
├── 証明書更新の処理
├── Envoyヘルスチェック
└── Envoyが死んだら再起動
2. Envoy(実際のプロキシエンジン)
├── pilot-agentが渡したブートストラップ設定で起動
├── istiodにxDS gRPC接続を確立して設定を受信
└── 実際のトラフィック処理(ルーティング、mTLS、メトリクスなど)
istio-proxyコンテナ内で実際にトラフィックを処理するエンジンはEnvoyだ。ただしIstioがpilot-agentというラッパーで包んでライフサイクル管理とistiod連携を追加したものだ。
xDS標準インターフェースの意義
この分離のおかげで:
- EnvoyはIstio以外にも複数のControl Planeと接続できる。 AWS App Mesh、Consul Connect、Gloo Edgeなども、Envoyをデータプレーンとして使いながら独自のControl Planeを提供している。
- IstioもEnvoy以外のプロキシをデータプレーンとして使える。 Ambient Meshのztunnelがこのケースだ — Envoyではなく、Rustで新しく書かれたL4専用プロキシで、istiodのxDSを通じて設定を受け取る。
istiod(Control Plane)
│
│ xDS API(標準インターフェース)
│
├──▶ Envoy(サイドカー / waypoint) — L7フル機能
│
└──▶ ztunnel(Rust、ノードレベル) — L4特化、軽量

xDSプロトコル ディープダイブ
先ほどistiodがEnvoyに設定を配信すると述べたが、その「配信」の具体的なプロトコルがxDSだ。
xDSの構成要素
xDSは「x Discovery Service」の略で、xにさまざまな文字が入り、それぞれ異なる種類の設定を担当する:
| xDS | 名称 | 役割 |
|---|---|---|
| LDS | Listener Discovery Service | どのポートでトラフィックを受けるか |
| RDS | Route Discovery Service | 受けたトラフィックをどのルールでルーティングするか |
| CDS | Cluster Discovery Service | ルーティング先(upstreamグループ)が何か |
| EDS | Endpoint Discovery Service | 各upstreamグループの実際のPod IP:Portは何か |
| SDS | Secret Discovery Service | mTLSに使う証明書と鍵 |
この5つが組み合わさると、Envoyがトラフィックを処理するのに必要なすべての情報が揃う。

具体例:カナリーデプロイ
reviewsサービスへのトラフィックの90%をv1に、10%をv2に送る設定:
# ユーザーが作成するIstio CRD
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: reviews-route
spec:
hosts:
- reviews
http:
- route:
- destination:
host: reviews
subset: v1
weight: 90
- destination:
host: reviews
subset: v2
weight: 10
---
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: reviews-dest
spec:
host: reviews
subsets:
- name: v1
labels:
version: v1
- name: v2
labels:
version: v2
istiodがこれをxDSに変換すると:
[LDS] Listener設定
"0.0.0.0:15001でアウトバウンドトラフィックを受けろ"
"Hostヘッダーが'reviews'なら → Route Config 'reviews-route'を使え"
│
▼
[RDS] Route設定
"reviews-route:"
" 90% → Cluster 'reviews.default.svc.cluster.local|v1'"
" 10% → Cluster 'reviews.default.svc.cluster.local|v2'"
│
▼
[CDS] Cluster設定
"reviews|v1: ロードバランシング=RoundRobin, サーキットブレーカー=5xx 3回で遮断"
"reviews|v2: ロードバランシング=RoundRobin, サーキットブレーカー=5xx 3回で遮断"
│
▼
[EDS] Endpoint設定
"reviews|v1 の実際のエンドポイント: [10.244.1.5:8080, 10.244.2.8:8080]"
"reviews|v2 の実際のエンドポイント: [10.244.3.2:8080]"
│
▼
[SDS] Secret設定
"このEnvoyの証明書: <X.509 cert>, 鍵: <private key>"
"信頼するCA: <root cert>"
gRPCストリーミングによるリアルタイム同期
xDSは双方向gRPCストリームを使用する。核心はEnvoyがistiodにまずConnection を確立するという点だ:

すべてのxDSを一つのgRPCストリームにまとめて送る方式をADS(Aggregated Discovery Service)と呼ぶ。LDS/RDS/CDS/EDSが別々に来ると順序が乱れる可能性があるため(例:Routeが参照するClusterがまだ届いていない)、一つのストリームで順序を保証しながら送る。
istiod内部の処理フロー
[Kubernetes API Server]
│
│ Watch(Service、Endpoint、Pod、Istio CRDs)
│
▼
[istiod: Config Controller]
│
│ "reviews ServiceのEndpointが変更された"
│ "VirtualService 'reviews-route'が新しく作成された"
│
▼
[istiod: xDS Generator]
│
│ 変更されたリソース → 影響を受けるEnvoyを計算
│ → 該当Envoyに合わせたxDS設定を生成
│
│ ★ 核心:すべてのEnvoyに同じ設定を送るわけではない
│ 各Envoyの位置(どのPod、どのネームスペース)に応じて
│ 必要な設定だけを選んで送る
│
▼
[istiod: xDS Server]
│
│ 変更された設定を該当EnvoyのgRPCストリームでPush
│
▼
[各Envoy] ── 設定を適用(hot reload、再起動なし)
VirtualService変更時の全体フロー
① kubectl apply -f virtualservice.yaml
│
▼
② K8s API ServerがVirtualServiceリソースをetcdに保存
│
▼
③ istiodがwatchしていて変更イベントを受信
│
▼
④ istiodが該当VirtualServiceの影響を受けるEnvoyを計算
│
▼
⑤ 各Envoyに合わせたRDS(Route)設定を生成
│
▼
⑥ すでに開いているgRPCストリームを通じて該当EnvoyにPush
│
▼
⑦ Envoyが新しいRoute設定をhot reloadで即座に適用
│
▼
⑧ 次のリクエストから新しいルーティングルールが適用される
(既存の接続は影響なし、新しい接続から適用)
この全体の過程が再起動なしで、数秒以内に行われる。
実際の確認コマンド
# 特定PodのEnvoyが持つListener設定(LDS)
istioctl proxy-config listeners <pod-name>
# Route設定(RDS)
istioctl proxy-config routes <pod-name>
# Cluster設定(CDS)
istioctl proxy-config clusters <pod-name>
# Endpoint設定(EDS)
istioctl proxy-config endpoints <pod-name>
# 全設定をJSONでダンプ
istioctl proxy-config all <pod-name> -o json
これらのコマンドは該当PodのEnvoy admin API(15000ポート)に接続して、現在適用されているxDS設定を読み取る。
istiodの配置と動作
istiodはワーカーノードで動く
istiodは一般的なワーカーノードで動く普通のDeploymentだ。マスターノード(K8s Control Planeノード)で動くわけではない。「Istio Control Plane」という用語で混乱しがちだが、これはIstioのControl Planeであり、KubernetesのControl Plane(API Server、etcd、schedulerなど)とは別物だ。
Kubernetes Cluster
├── Master Node(K8s Control Plane)
│ ├── kube-apiserver
│ ├── etcd
│ ├── kube-scheduler
│ └── kube-controller-manager
│
├── Worker Node 1
│ ├── kubelet
│ ├── istiod(Istio Control Plane) ← ここにスケジューリングされ得る
│ ├── Pod A + istio-proxy
│ └── Pod B + istio-proxy
│
├── Worker Node 2
│ ├── kubelet
│ ├── Pod C + istio-proxy
│ └── Pod D + istio-proxy
# istiod Deployment(簡略化)
apiVersion: apps/v1
kind: Deployment
metadata:
name: istiod
namespace: istio-system
spec:
replicas: 1 # 本番環境では2-3でHA構成
template:
spec:
containers:
- name: discovery
image: istio/pilot:1.24.0
ports:
- containerPort: 15010 # xDS gRPC(平文)
- containerPort: 15012 # xDS gRPC(mTLS)
- containerPort: 443 # Webhook(サイドカーインジェクション)
- containerPort: 15014 # モニタリング
Kubernetes schedulerがリソース状況に応じて任意のワーカーノードに配置する。Serviceとして公開されるので、どのノードにあってもすべてのEnvoyがアクセスできる。
mTLSとZero Trust
TLS vs mTLS
通常のTLS(HTTPS)
ブラウザでhttps://github.comにアクセスする時に起こること:

通常のTLSの核心的特徴:サーバーだけが自分が誰かを証明する。 クライアントは証明書を提出しない。
mTLS(Mutual TLS)
クライアントも自分が誰かを証明書で証明する:

Mutual = 相互的。 双方が互いに「お前は誰だ?」と尋ね、双方とも証明書で答える。
なぜKubernetesでmTLSが必要なのか
通常のKubernetesクラスタでのPod間通信はデフォルトで平文だ。これが問題になる理由:
- ノードのネットワークにアクセスできる誰かがパケットをキャプチャすると内容が丸見え
- Pod AがPod Bにリクエストを送る時、Pod Bは「これが本当にPod Aが送ったものか」を判別する方法がない
これがZero Trustの核心的前提だ — 「ネットワーク上の位置(同じクラスタ、同じVLANなど)を信頼の根拠としない。」代わりに、すべての通信で相手方の身元(identity)を暗号学的に検証する。
IstioでmTLSが動作する原理
Step 1:ワークロードID体系 — SPIFFE
Istioは各ワークロードにSPIFFE ID(Secure Production Identity Framework for Everyone)という固有の身元を付与する:
spiffe://cluster.local/ns/default/sa/reviews
───────────── ────────── ──────────
trust domain namespace service account
このIDはKubernetesのServiceAccountにマッピングされる。PodがどのServiceAccountで実行されるかによってSPIFFE IDが決まる。
Step 2:証明書発行プロセス

Envoyが起動するとistiodにSDSリクエストで証明書を要求する。istiodはK8s API Serverを通じて該当PodのServiceAccountを検証した後、署名されたX.509証明書と秘密鍵を発行して返す。
Step 3:実際のmTLSハンドシェイク
Pod A(productpage)がPod B(reviews)にリクエストを送る時を図で示すと以下の通りだ。

重要なのは、アプリはこの流れを知らないということが核心だ。上でずっと一貫して述べてきたように、すべてのトラフィックの処理はEnvoyが行っている。mTLSも同様にEnvoyが行っている。
この全体の過程で、アプリは:
- 平文HTTPを送る → Envoyが暗号化
- 平文HTTPを受ける → Envoyが復号化
- 証明書を管理する必要なし → Envoy + istiodが自動処理
- コードにTLS関連のロジックが一切不要
mTLS + AuthorizationPolicy = Zero Trust
mTLSだけでは「暗号化 + 相互認証」だ。ここにIstioのAuthorizationPolicyを加えると、「誰が誰にアクセスできるか」まで制御できる:
apiVersion: security.istio.io/v1
kind: AuthorizationPolicy
metadata:
name: reviews-policy
namespace: default
spec:
selector:
matchLabels:
app: reviews
rules:
- from:
- source:
principals:
- "cluster.local/ns/default/sa/productpage" # このSPIFFE IDのみ
to:
- operation:
methods: ["GET"] # GETのみ許可
paths: ["/api/reviews/*"] # このパスのみ許可
ネットワークIPではなく暗号学的に検証されたワークロードの身元を基準に判断するのがZero Trustの核心だ。
従来のネットワークセキュリティ:
"10.244.1.0/24帯域からのトラフィックは許可" ← IPベース、スプーフィング可能
Zero Trust(Istio mTLS):
"spiffe://cluster.local/ns/default/sa/productpage が
署名された証明書で自身を証明した場合のみ許可" ← 暗号学的検証
mTLSモード
apiVersion: security.istio.io/v1
kind: PeerAuthentication
metadata:
name: default
namespace: istio-system # メッシュ全体に適用
spec:
mtls:
mode: STRICT # or PERMISSIVE
- PERMISSIVE — mTLSと平文の両方を受け入れる。メッシュにまだ含まれていないサービスがある場合に使用。Istioを段階的に導入する際に有用。
- STRICT — mTLSのみ許可。証明書なしの平文トラフィックは拒否。完全なZero Trust。
Istio + CNIの組み合わせ(Cilium、Calico、Flannel)
ここまでIstioがトラフィックをどうインターセプトし(iptables)、どうルーティングし(xDS)、どう暗号化するか(mTLS)を見てきた。しかしこれらすべてはPod間ネットワークがすでに動作しているという前提の上にある。その「Pod間ネットワーク」を作ってくれるのがCNIだ。IstioはCNIの上で動作するため、どのCNIを使うかによってIstioの動作方式とパフォーマンスが変わる。
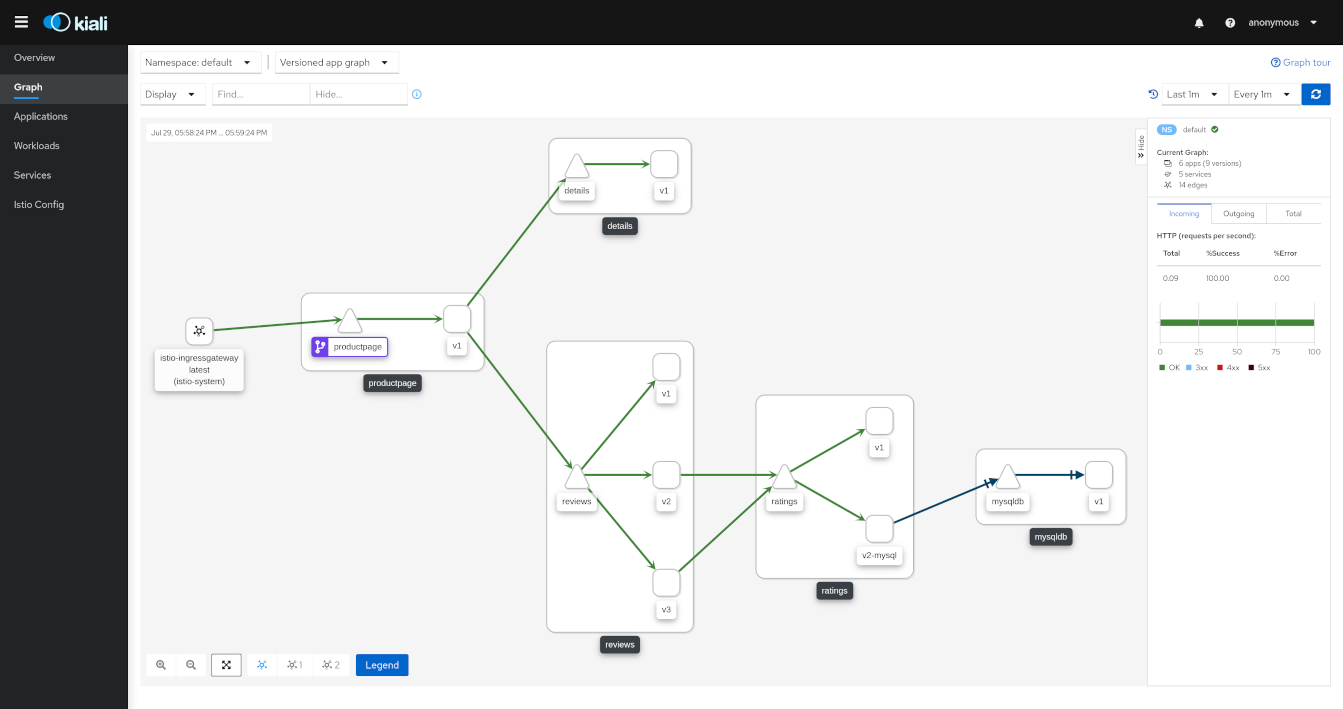 出典: https://pre-v1-41.kiali.io/documentation/v1.36/features/
出典: https://pre-v1-41.kiali.io/documentation/v1.36/features/
サービスメッシュを導入すると上のようにサービス間トラフィックフローをリアルタイムで可視化できる。このダッシュボードはKialiで、Istioと共に使われる代表的なオブザーバビリティツールだ。
CNI vs Service Mesh:レイヤーが異なる

CNIは「PodがIPを受け取り他のPodと通信できるようにする基本ネットワークインフラ」であり、Service Meshは「その上でアプリケーションレベルのトラフィックを精密に制御する階層」だ。
Flannel + Istio
最もシンプルな組み合わせ。FlannelはL3オーバーレイ(VXLAN)だけを行い、NetworkPolicyもサポートしないのでIstioと衝突することがほぼない。ただしFlannelがやってくれることが少ないため、ネットワークポリシーはすべてIstioのAuthorizationPolicyに依存することになる。k3sのデフォルトCNIがFlannelなので、最も簡単に始められる組み合わせだ。
Calico + Istio
CalicoがL3/L4 NetworkPolicyを担当し、IstioがL7ポリシーを担当する階層型セキュリティ構造を作れる。CalicoとIstio Ambient Meshを組み合わせると、ztunnelがすべてのトラフィックを暗号化してIDを検証し、CalicoがCNIレベルでどの接続が許可されるかを制御する縦深防御戦略を実現できる。
Cilium + Istio
Ciliumがカーネルレベルのネットワーキング(IP管理、ルーティング、L3/L4ポリシー)を処理し、Istioがアプリケーション層(HTTPルーティング、mTLS ID、きめ細かな認可ポリシー、トラフィックシェーピング)を処理するのが推奨アプローチだ。ただしCiliumのkubeProxyReplacementがeBPFソケットレベルのロードバランシングを行うとIstioのiptables REDIRECTをバイパスし得るため、socketLB.hostNamespaceOnly: true設定が必要だ。
全体像のまとめ
階層構造
ユーザーが記述するもの:
VirtualService、DestinationRule、AuthorizationPolicy(Istio CRDs)
│
▼
istiodがやること:
K8sリソース + Istio CRD → xDS設定に変換 → 各EnvoyにgRPCでプッシュ
+ 証明書発行/更新(CA)
+ Mutating Webhookでサイドカー自動インジェクション
│
▼
Envoy(istio-proxy)がやること:
xDSで受け取った設定に従って実際のトラフィックを処理
- ルーティング、ロードバランシング、リトライ
- mTLSハンドシェイク
- メトリクス収集、トレーシングヘッダー伝播
- 認可ポリシーの適用
│
▼
iptables(またはeBPF)がやること:
アプリ ↔ Envoy間の透過的なトラフィックリダイレクト
(アプリは自分が直接通信していると思っている)
依存関係のまとめ
netfilter(カーネル)
└── iptablesルールでトラフィックをEnvoyにREDIRECT
└── Envoy(istio-proxy)
├── xDSでistiodから受け取ったルーティングルールを適用
├── SDSでistiodから受け取った証明書でmTLSを実行
├── SPIFFE IDベースの相互認証
└── AuthorizationPolicyでL7認可を判定
└── istiod(Control Plane)
├── K8s API watch → xDS設定の生成/配布
├── CAとして証明書を発行/更新
└── Webhookでサイドカーを自動インジェクション
結論:「カーネルのnetfilterがトラフィックをインターセプトし → Envoyが処理し → istiodが管理する」という3層構造において、mTLSはEnvoy層で実行される暗号化/認証メカニズムであり、その証明書ライフサイクルをistiodが自動で管理している。

おわりに
結局Istioは「カーネルのnetfilterがトラフィックをインターセプトし → Envoyが処理し → istiodが管理する」という3層構造だ。アプリコードを1行も変えずにmTLS、トラフィックルーティング、オブザーバビリティを得られる理由は、これらの層が透過的に動作するからだ。前回の記事で扱ったnetfilter、iptables、CNIといったカーネル/ネットワーク基盤の知識があれば、Istioの動作原理がより自然に理解できるだろう。